Abstract
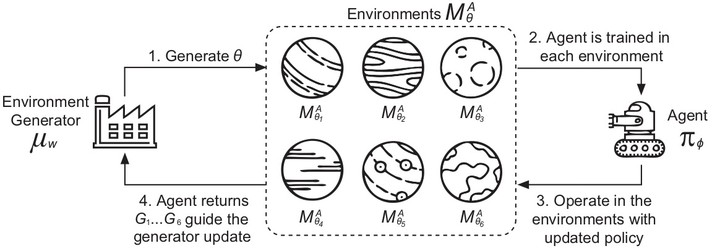
In typical reinforcement learning (RL), the environment is assumed given and the goal of the learning is to identify an optimal policy for the agent taking actions through its interactions with the environment. In this paper, we extend this setting by considering the environment is not given, but controllable and learnable through its interaction with the agent at the same time. Theoretically, we find a dual Markov decision process (MDP) wrt the environment to that wrt the agent, and solving the dual MDP-policy pair yields a policy gradient solution to optimizing the parametrized environment. Furthermore, environments with non-differentiable parameters are addressed by a proposed general generative framework. Experiments on a Maze generation task show the effectiveness of generating diverse and challenging Mazes against agents with various settings.
Ying Wen
Assistant Professor
My research interests include multi-agent learning and reinforcement learning..