Modelling Bounded Rationality in Multi-Agent Interactions by Generalized Recursive Reasoning
Abstract
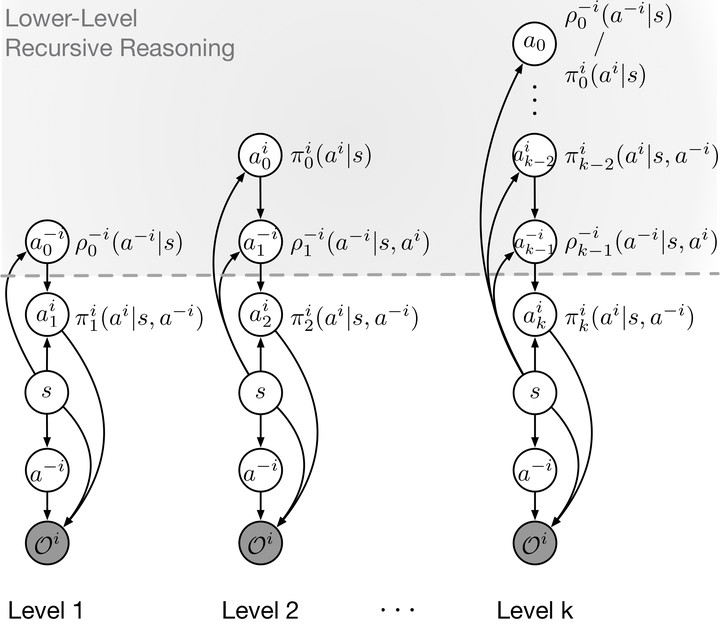
We propose a new reasoning protocol called generalized recursive reasoning (GR2), and embed it into the multi-agent reinforcement learning (MARL) framework. The GR2 model defines reasoning categories: level-0 agent acts randomly, and level-k agent takes the best response to a mixed type of agents that are distributed over level 0 to k−1. The GR2 leaners can take into account the bounded rationality, and it does not need the assumption that the opponent agents play Nash strategy in all stage games, which many MARL algorithms require. We prove that when the level k is large, the GR2 learners will converge to at least one Nash Equilibrium (NE). In addition, if lower-level agents play the NE, high-level agents will surely follow as well. We evaluate the GR2 Soft Actor-Critic algorithms in a series of games and high-dimensional environment; results show that the GR2 methods have faster convergence speed than strong MARL baselines.
Ying Wen
Assistant Professor
My research interests include multi-agent learning and reinforcement learning..