世界模型到底在建模什么:从预测未来到复用经验
很多人听到世界模型,第一反应是一个能模拟世界的模型。比如它能预测游戏下一帧,能生成一段未来视频,能在机器人动手前想象物体会怎么移动,或者能在强化学习里预测一个动作之后环境会发生什么。
这个直觉没有错。世界模型确实和预测未来有关。但如果我们只把它理解成更大的模拟器,就会错过一个更重要的问题:对一个要行动的智能体来说,预测未来只是第一步。真正困难的是,它应该保留哪些未来信息,丢掉哪些未来信息,以及如何把一次经验变成以后可复用的能力。
这篇文章想先把世界模型这个词讲清楚。现在很多人说的世界模型,其实不是同一个架构,而是一个更大思想框架下的不同实现。强化学习里的状态预测、视频生成里的未来画面、机器人里的状态-动作模型、智能体系统里的长思考、规划和记忆,都可以放进这个大框架里。它们都在处理未来相关知识,只是处理的对象、条件和用途不同。123
还有一条容易被低估的线索,是物理信号和科学世界模型。很多 AI 系统学习的是人类已经写下、拍下、压缩和标注过的世界;但真实世界进入模型之前,往往已经经过传感器、采样、校准、显示、压缩和人类命名。光谱、振动、电流、温度、遥感、实验仪器读数、连续动力系统和科学仿真这类数据提醒我们:世界模型不只是在文字和 RGB 图像上预测未来,也可能是在带噪声、带仪器偏置、带时间尺度的测量流中学习规律。45
在这个基础上,我们再引入三重世界模型。它把问题拆成三件事:环境如何反馈,智能体如何形成当前判断,经验如何变成外部知识。为了让后面的讨论更容易读,本文先用中文名字讲:可交互客观世界(W1)、主观世界模型(W2)、外部知识世界(W3)。
最后,我们会引出一个更窄的判断:下一代智能体可能真正缺的,不是更完整的世界副本,而是一层会选择可控未来的内部世界模型,也就是主观世界模型(W2)。后文还会用到一个评估概念:能力复利系数(Capability Compounding Coefficient, CCC)。它关心的不是一次任务分数,而是一次经验能否降低未来任务的成本。文章后半部分会更具体地说:这件事对训练方式、轨迹日志、数据收集和不同领域的系统设计到底有什么指导意义。特别是在具身和机器人里,它会导向一个和现有视觉-语言-动作模型、世界动作模型不完全相同的训练目标:不是只让模型更会输出动作或生成未来,而是让系统显式学会对象状态、任务阶段、可供性、失败恢复和经验复用。
先从大家熟悉的世界模型说起
如果从今天的技术语境看,世界模型大概有四种最常见的理解。
第一种来自强化学习。智能体在环境里行动,模型预测下一状态、奖励或价值。它回答的问题是:如果我现在做这个动作,环境接下来会怎样?这类模型对规划很重要,因为智能体可以先在内部试算,再决定真实行动。Dyna、World Models、MuZero、Dreamer 这条线,都是这个直觉的代表。1
第二种来自视频和空间生成。模型从文字、图像或视频生成未来画面。它回答的问题是:这个场景接下来可能长什么样?这类模型让人很容易联想到世界模拟器,因为它生成的是直观的视觉未来。V-JEPA 和 Sora 这类工作,让世界模型和视觉未来、空间一致性、物理或数字世界模拟之间的关系变得更明显。2
第三种来自机器人和具身智能。最典型的是世界动作模型(World Action Model, WAM),试图把动作和未来图像或未来状态放进同一个模型里。它们回答的问题是:在当前任务下,我应该怎么动,动完世界可能怎样变?这类系统很重要,因为它们把世界模型问题推向身体、物体、动作后果和失败恢复。但它们也让一个分歧变得更清楚:训练动作输出或未来画面,不等于训练一个会保留对象状态、任务阶段、身体约束和恢复线索的内部判断层。6
第四种来自大语言模型智能体。这里的世界不一定是物理空间,而可能是浏览器、代码库、终端、文档和工具系统。模型保存计划、工具调用、执行轨迹、测试结果和修复经验。它回答的问题是:过去的执行经验和外部知识,如何帮助我完成未来任务?ReAct、Reflexion 和 Voyager 等工作,已经展示了语言模型如何通过工具、反馈、反思和技能库把一次执行变成后续行动线索。3
这四种都可以叫世界模型,但它们不是同一种东西。
| 常见语境 | 世界模型通常指什么 | 它预测或保留的未来信息 | 还没自动解决的问题 |
|---|---|---|---|
| 强化学习 | 动作后的状态、奖励或价值 | 环境会怎样变化 | 开放任务、长期经验、外部知识复用 |
| 视频生成 | 未来画面或空间结构 | 场景接下来长什么样 | 哪些变量可控,哪些细节对行动重要 |
| 具身智能/机器人 | 视觉、身体状态到动作或动作后果 | 下一步怎么动,物体如何变化 | 失败原因、恢复路径、任务阶段 |
| 大语言模型智能体 | 记忆、计划、工具轨迹、测试和技能 | 哪些历史线索可帮助未来任务 | 旧记忆是否过期,当前状态是否匹配 |
这个表的重点不是分类,而是消除一个误会。现在大多数人说的世界模型,是一个大思想框架下的不同实现。它们共享一个抽象问题:在某些条件下,预测或保留对未来有用的信息。但它们的实现可以完全不同。
所以,当我们讨论下一代智能体需要什么样的世界模型时,不能只问模型能不能预测未来。还要问,它预测的未来是否可行动,是否和目标有关,是否能帮助失败恢复,是否能沉淀成未来任务可复用的经验。
Takeaway:不要只把成功样本做成输入到输出。对行动系统,更有价值的是把目标、动作、预测后果、真实反馈、失败修正和后续复用放在同一条轨迹里。
预测未来还不够
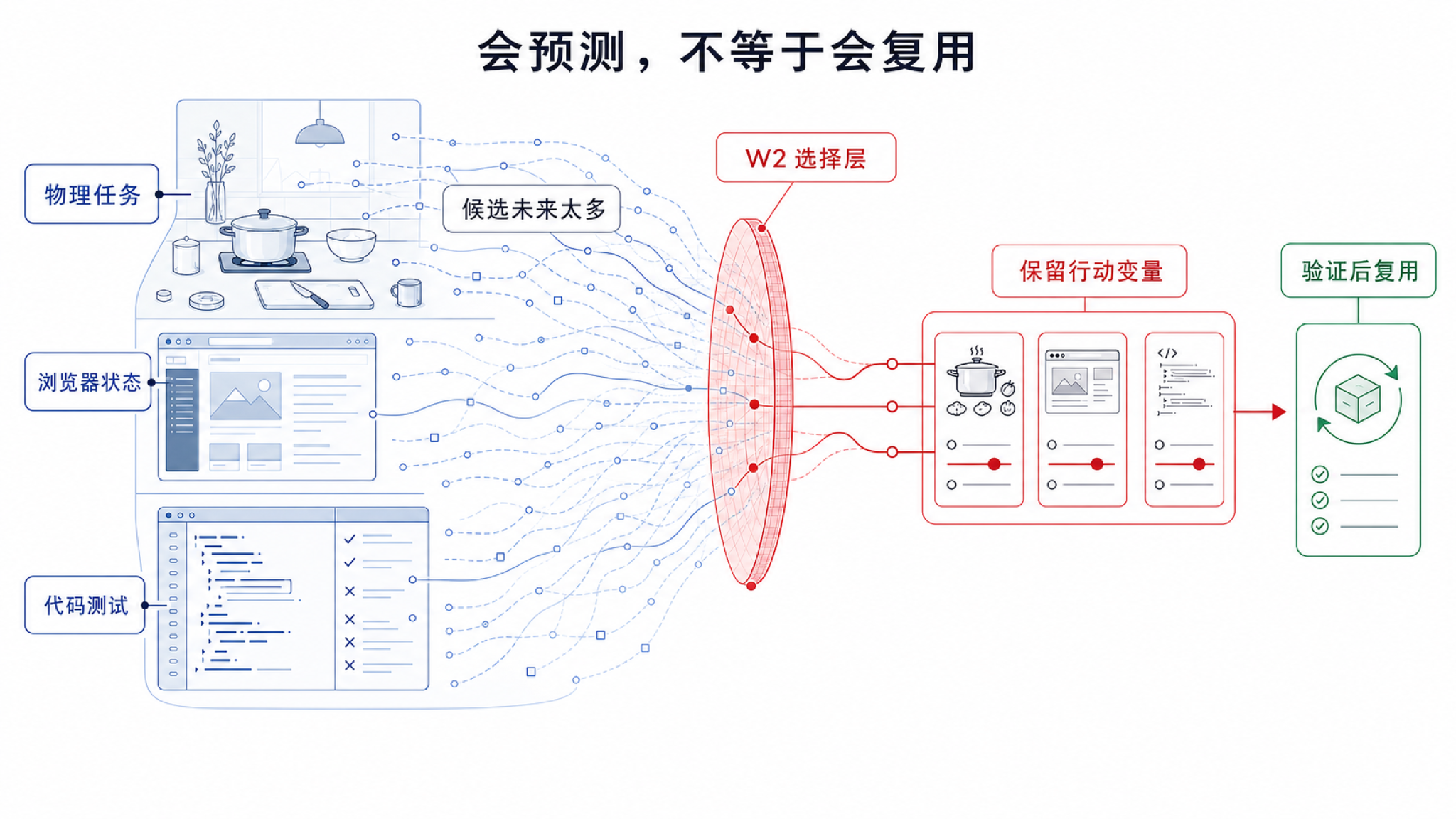
这里有一个容易被忽略的差别:能预测未来,不等于知道该保留什么未来。
一个视频模型可能能生成逼真的厨房未来画面,但机器人真正需要的不是画面里每个反光和纹理,而是杯子在哪里、能不能抓、手臂会不会碰到障碍物、失败后怎么调整。一个浏览器智能体可能保存了完整操作记录,但当前页面刷新后,旧按钮位置可能已经不能用了。一个代码智能体可能保存了一整段修复过程,但真正有价值的是哪个测试验证了哪个假设、哪个补丁路线失败过、哪个模块和哪个模块有隐含耦合。
这些例子和大家熟悉的世界模型直接相关。它们都不是说预测未来没用,而是说未来信息太多了。对行动系统来说,关键不是把未来越预测越完整,而是在有限容量下选择对行动最有用的未来。
这就是本文的动机。我们关心的世界模型,不只是一个未来预测器,而是一个帮助智能体选择未来知识的机制。
我们对世界模型的定义
可以先不用公式,给一个通俗定义:
世界模型是智能体在当前情况、当前目标、可能动作和不确定性下,对未来有用信息的预测或压缩。
当前情况包括它看到了什么、已经做过什么、工具和权限是什么、页面或物理环境处于什么状态。更严格地说,智能体看到的通常不是世界本身,而是某种测量结果:图像、日志、API 返回、传感器读数、实验记录或人类写下的描述。每种测量都有采样方式、噪声、延迟、校准和偏置。当前目标决定了什么信息重要。拿杯子和清理桌面需要关注不同变量;修复故障和重构代码也需要关注不同线索。可能动作决定了它能改变什么。它能点击按钮、运行测试、移动机械臂、询问用户,也可能无法改变某些背景因素。不确定性则提醒我们,很多关键状态没有被直接看到,必须通过行动和反馈逐步推断。
最后被预测或保留的未来信息也不一定是下一帧图像。它可以是下一状态、奖励、价值、动作后果、失败风险、工具状态、测试结果、可复用规则、技能、修复模式,甚至是某条旧记忆现在不能信。
所以这里有四个输入:当前情况、当前目标、可能动作和不确定性。输出也不是单一格式,而是未来有用信息。这个定义比较宽。它允许我们把强化学习模型、视频模型、机器人模型和大语言模型智能体记忆放在一张地图上比较。但它也会自然引出一个更严格的问题:在大世界里,智能体不可能保留一切,那么它应该保留什么?
如果不能保留一切,应该保留什么
世界太大,而智能体容量有限。这句话听起来抽象,但在实际系统里非常具体。
代码仓库有成千上万行文件。浏览器页面有大量文字、按钮、弹窗、状态和后台请求。机器人摄像头里有无数像素。对话历史里有大量可能相关也可能无关的信息。模型上下文再长,也不可能把所有东西都当成同等重要。
普通压缩可以按预测误差来保留信息:什么最能帮助预测未来,就保留什么。普通记忆可以按相似度检索:什么看起来像当前问题,就取回什么。普通视觉模型可以按画面连贯性建模:什么能让未来视频更真实,就生成什么。
但对一个要行动的智能体来说,这些标准都不够。它真正需要优先保留的是当前目标下重要、自己能影响、失败时能帮助恢复、以后能被验证和复用的信息。
可以把这叫做可行动的压缩。
城市地图的例子很直观。一张完整地图可以标出所有街道、店铺和地形。但如果你正在赶火车,你真正需要的是当前位置、到车站路线、哪些路封了、哪种交通方式还来得及。完整地图有用,但当前任务需要的是被目标和行动重新折叠过的地图。
智能体也一样。它不需要在内部复制整个世界,而需要一张知道该看什么的地图。
| 普通世界模型可能关心 | 行动智能体更需要关心 |
|---|---|
| 未来可能发生什么 | 当前目标下哪些未来重要 |
| 世界看起来会怎样 | 哪些状态能被我改变 |
| 如何重建更多细节 | 哪些细节可以安全丢掉 |
| 当前策略能否成功 | 失败会是什么样,如何恢复 |
| 这次任务能否完成 | 这次经验能否降低下次成本 |
这个选择问题,是三重世界模型要解决的核心。
Popper 的三个世界理论作为起点
三重世界模型这个名字不是凭空来的。一个重要启发是 Karl Popper 的三个世界理论。Popper 把世界分成物理对象和过程的世界、主观经验和心理状态的世界、以及客观知识内容的世界。后者包括理论、问题、论证、书籍、数学对象和文化产物等,它们一旦被写下来,就不再只是某个人脑中的瞬间想法,而可以被别人检查、批评、继承和改造。78
这个划分对 AI 很有启发。今天的智能体也同时面对三类东西:它要在一个会被动作改变的环境里行动;它必须在内部形成当前判断;它还会依赖外部文档、代码、测试、工具、技能和记忆。很多系统问题,恰恰来自这三类东西被混在一起。比如,把一段旧记忆当成当前状态,把一份文档当成已经验证过的行动知识,或者把一个会生成未来画面的模型当成已经知道该怎么行动。
但本文不是简单照搬 Popper。Popper 的三个世界主要是哲学和知识论框架;这里的三重世界模型是面向智能体工程的操作性框架。可交互客观世界(W1)不只包括物理世界,也包括浏览器、代码库、终端和社会反馈。主观世界模型(W2)不是人类意识,而是智能体在当前目标下的内部压缩和判断。外部知识世界(W3)也不只是抽象理论,而包括能被系统读写、测试、执行和复用的知识产物。
三重世界模型:把环境、内部判断和外部知识分开
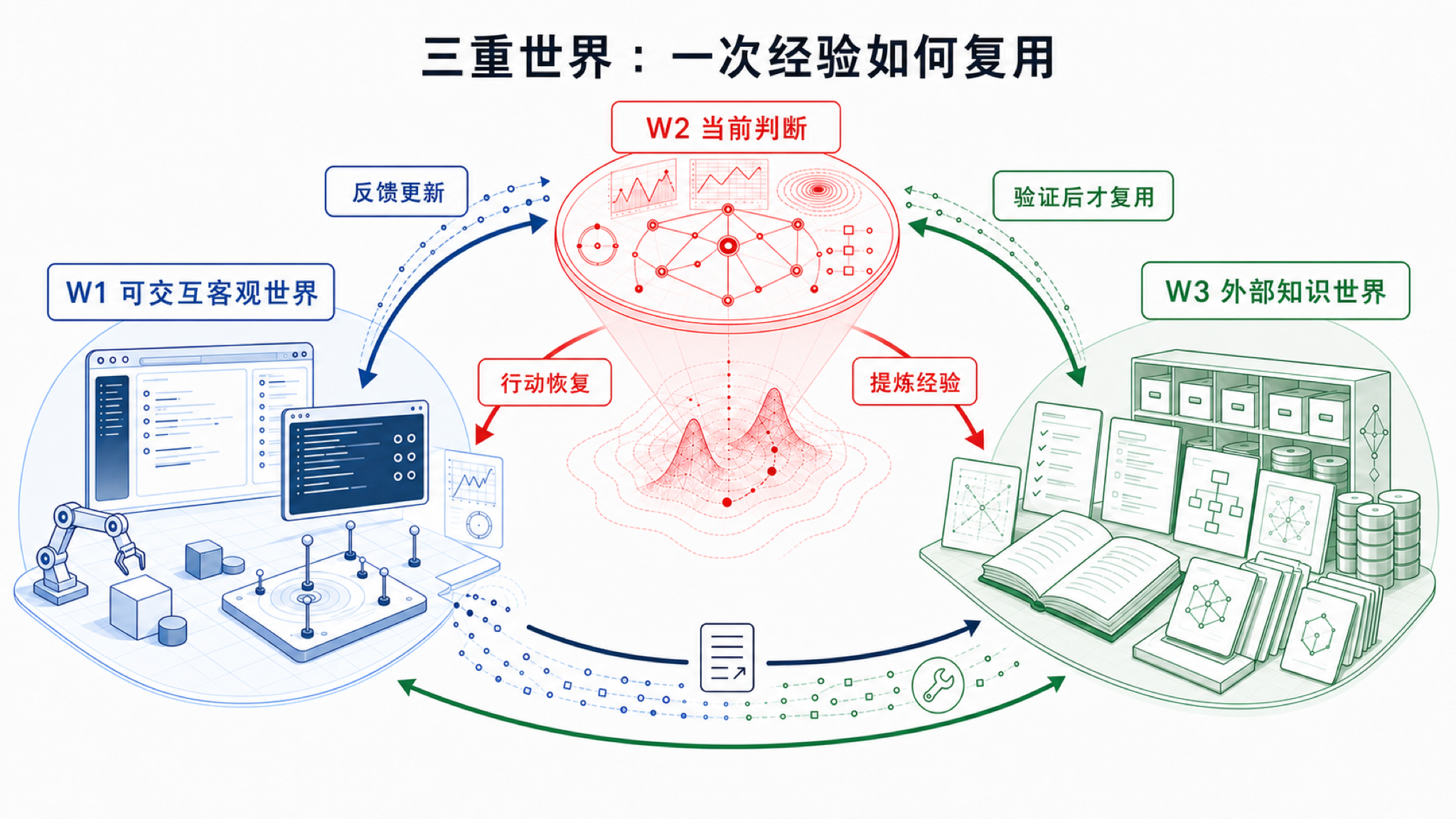
三重世界模型不是为了制造新术语,而是为了把三件经常混在一起的东西分开:可交互客观环境、智能体内部判断、外部可复用知识。
第一层叫可交互客观世界(W1)。只要智能体的动作会改变它,它就是可交互客观世界的一部分。机器人厨房、浏览器页面、代码仓库、命令行、多人协作环境、交互式模拟器,都可以在这个层里。它的作用是提供反馈:动作有没有生效、状态有没有改变、哪里失败了、还有哪些约束。对物理和科学任务来说,W1 还要包括测量接口本身:传感器、仪器、采样频率、校准状态、单位系统和观测延迟。否则模型可能把仪器偏差当成世界规律。
第二层叫主观世界模型(W2)。这里的主观不是自我意识,而是任务相关、智能体视角、容量受限的内部压缩。同一个页面、同一个房间、同一个代码仓库,在不同目标下应该被压缩成不同状态。主观世界模型关心的是:我现在相信世界处于什么状态?哪些变量与目标有关?我能改变什么?失败风险在哪里?下一个动作可能产生什么后果?
第三层叫外部知识世界(W3)。它包括语言、代码、测试、文档、规则、工具、技能、日志、来源笔记和验证器输出,也包括科学任务里的方程、单位、守恒量、尺度律、因果图、实验协议、误差模型和仪器校准说明。外部知识世界的特点是可以保存、共享、组合。一次经验如果被验证并写成测试、规则、技能或科学 artifact,就从临时轨迹变成了知识产物。
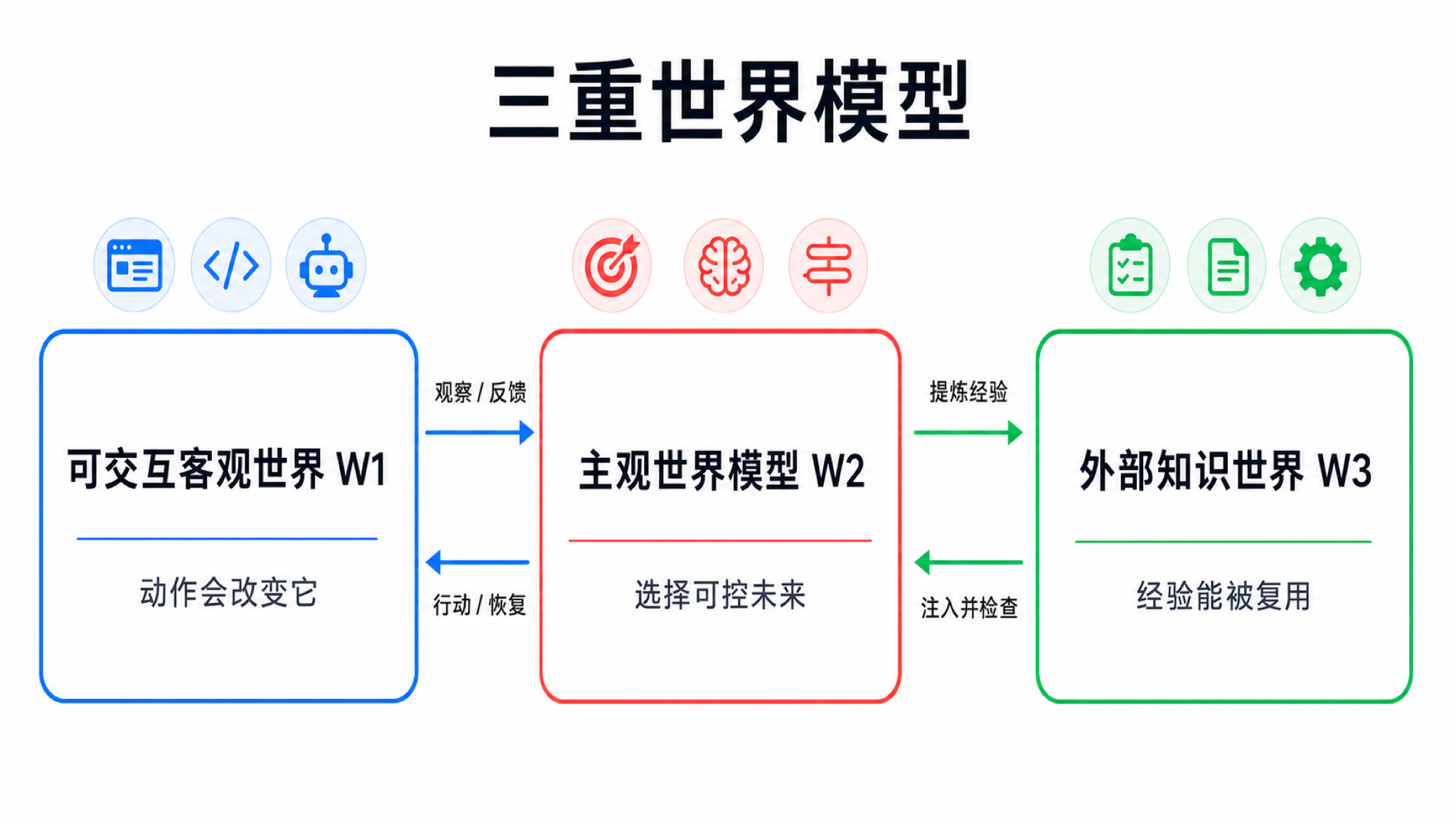
这个框架里最容易混淆的是主观世界模型(W2)和外部知识世界(W3)。长上下文、检索增强、记忆库、技能文件、测试用例,大多属于外部知识世界或它的基础设施。它们是外部知识,不等于当前判断。一个旧测试可能仍然有用,也可能因为代码结构变化而过期。一个浏览器操作脚本可能适用于旧页面,不适用于新页面。主观世界模型的职责,是判断这些外部知识在当前可交互客观世界状态下是否仍然可用。
也就是说,三重世界模型不是说人工智能系统要机械地分成三个模块。它说的是,任何能长期行动和学习的智能体,都要处理这三种角色:和世界交互、形成当前判断、保存可复用知识。
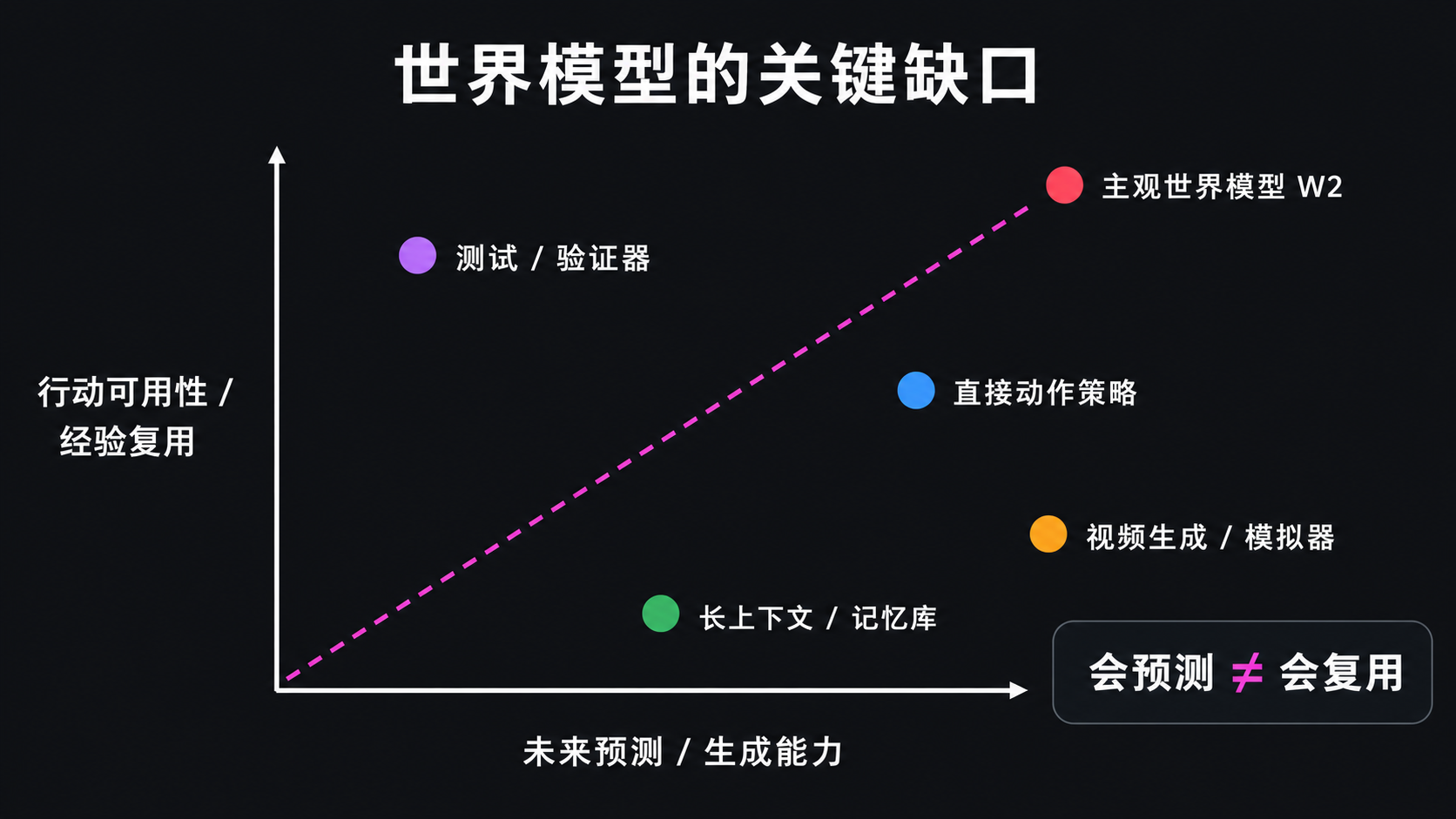
为什么主观世界模型是关键缺口
很多当前系统已经很强,但强在不同位置。
视频和交互式生成模型强化了 W1,因为它们能生成或模拟未来世界。智能体运行框架、记忆、工具协议和代码测试强化了 W3,因为它们让系统能保存和调用外部知识。机器人策略和工具工作流强化了直接执行,因为它们能把语言、视觉或文档变成动作。
这些进展都重要。但它们容易绕过主观世界模型。
第一种绕过方式是更强模拟器。如果我们能生成更真实的视频、更大的交互环境、更丰富的合成数据,是不是就有世界模型了?部分是。但问题是,智能体仍然要知道哪些模拟结果值得相信,哪些变量和当前目标相关,哪些干预真的能改变结果。模拟世界不等于知道该保留什么。
第二种绕过方式是更长记忆。如果我们保存完整执行记录、工具调用、历史经验、技能库,是不是就有智能了?也只是部分。记忆会过期,会污染,会脱离当前状态。没有主观世界模型的范围和证据检查,外部知识世界可能从资产变成噪声。
第三种绕过方式是直接动作策略。如果模型能直接从语言或视觉输出动作,是不是不需要内部世界模型?在很多任务上可能足够。但一旦失败,系统需要知道为什么失败、状态哪里变了、下一步如何恢复、哪些经验以后还可用。直接动作可以成功,但不自动带来可解释的恢复和复用。
具身机器人把这个问题放大了。VLA 路线的优势,是把互联网规模的视觉语言知识和机器人示范接起来,让模型能从图像、指令和身体状态直接输出动作。WAM 或 WorldVLA 一类路线又进一步,把动作和未来图像、未来状态联合建模。它们都值得认真作为底座或强基线使用,而不是被简单否定。
如果用今天大模型训练的语言类比,VLM、视频模型和物理世界模型更像大规模预训练:它们学习外观、语义、空间和动态先验。VLA、WAM 和示范轨迹更像面向行动的指令微调:它们学习在给定指令和观察下输出合理动作或动作后的未来。主观世界模型要补的是更接近强化学习后训练的一层:通过真实或高质量模拟交互、验证器、失败反馈和跨任务复用,让系统学会哪些变量可控、什么时候该相信模型、失败后怎么恢复、哪些经验值得沉淀。
但这里有一个根本分歧:现有 VLA/WAM 路线公开可见的主要训练压力,往往放在动作是否像示范、未来是否像真实轨迹;主观世界模型还要优化哪些状态由我可控、失败时怎样恢复、经验以后能不能复用。 如果一个机器人只学会在当前画面下输出一个合理动作,却不知道杯子是否已经被抓住、抽屉是否真的打开、当前任务到了哪一阶段、夹爪偏移后应该重试还是换策略,那么它在熟悉分布上可以很好看,但在遮挡、布局变化、长程任务和失败恢复上会缺少可检查的内部判断。
Takeaway:VLA 和 WAM 可以作为动作底座或训练信号,但主观世界模型需要学习到对象状态、任务阶段、可供性、身体约束、失败类型、恢复动作和仿真可信度。
| 常见路线 | 它提供了什么 | 为什么还不自动是主观世界模型 |
|---|---|---|
| 更强模拟器 | 更丰富的未来想象 | 未必知道哪些未来对当前目标和行动重要 |
| 更长记忆 | 更多历史记录和经验 | 未必知道记忆是否仍适用于当前状态 |
| 视觉-语言-动作模型 | 更快从图像、语言到动作 | 未必暴露对象状态、任务阶段、可供性和失败恢复 |
| 世界动作模型 | 把动作和未来图像或状态连起来 | 如果只生成未来或动作,仍未必形成可复用的内部判断 |
| 更高测评分数 | 终局结果更好 | 未必说明机制、迁移和经验复利 |
这就是我们认为主观世界模型必要的地方:它是把可交互客观世界的反馈和外部知识世界的知识连接成可行动判断的中间层。
主观世界模型的核心原则可以说得很朴素:
有限智能体应该把表示容量优先花在与当前目标相关、并且自己能够影响的未来上。
这就是可控性感知压缩。它不是压缩一切,也不是预测一切,而是把有限注意力花在可行动的未来上。具体说,主观世界模型会反复问四个问题:这件事和当前目标有关吗,我能影响它吗,失败时它能帮我恢复吗,它以后能变成规则、测试或技能吗?
一个浏览器智能体不应该平均记住页面上所有文字,而应该记住当前任务相关的控件、登录状态、错误提示、页面是否刷新、刚才点击是否真的生效。一个机器人不应该只记住图像里最显眼的像素,也不应该只模仿下一段动作,而应该记住目标物体、可抓取性、遮挡、手臂状态、任务阶段和失败后的恢复动作。一个代码智能体不应该只保存完整执行记录,而应该把哪个测试验证了哪个假设、哪个补丁失败过、哪个模块和哪个模块耦合,变成可复用的知识产物。一个科研智能体也不应该只保存论文摘要或实验截图,而应该保留测量条件、变量定义、误差来源、可干预参数、反事实问题和后来可复验的模型假设。
一旦这样看,主观世界模型不是额外装饰层,而是大世界下的选择机制。
怎么判断一个系统真的有主观世界模型
不能靠名字判断。一个系统可以没有模块叫 W2,但功能上满足主观世界模型。反过来,一个系统就算画了 W2 模块,如果不能提升恢复、迁移和经验复用,也不应该算有效的主观世界模型。
我们需要看行为证据。
第一,它是否能在容量有限时保留关键状态。不是看它能不能记住全部上下文,而是看它在任务切换、干扰变量、部分观察下,能不能保留真正影响目标的变量。
第二,它是否能预测动作后果。它点了按钮、改了代码、移动了物体之后,是否能预期世界会怎么变,并在观察到不一致时更新判断。
第三,它是否能从失败中恢复。强系统不是不失败,而是失败后不反复撞同一个错误。它应该能识别失败类型、缩短恢复路径,并把失败经验沉淀下来。
第四,它是否能把经验变成可复用外部知识。一次成功如果不能降低下次任务成本,它更像一次性运气。经过验证、带适用范围、能在未来减少搜索或错误的知识产物,才是真正的知识积累。
第五,这些收益是否在隐藏任务上仍然存在。否则我们可能只是在测基准记忆、提示技巧或数据泄漏。ARC-AGI-3、OSWorld、SWE-bench 这类评测的共同价值,不是它们已经证明了 W2,而是它们把隐藏规则、真实软件状态、测试验证器和未来任务迁移暴露出来,让经验复用不再只靠主观感觉判断。9
Takeaway:不要只看当次成功率。更应该看隐藏任务上的动作数、重复失败率、恢复步数、人工接管次数、验证成本和后续复用收益。
能力复利系数(Capability Compounding Coefficient, CCC):经验有没有带来能力复利
为了衡量经验是否真的有用,我们提出能力复利系数(Capability Compounding Coefficient, CCC)。
这个名字听起来抽象,但问题很朴素:
一个经过验证的经验,未来到底帮系统省下了多少成本?
普通测评分数回答这次做成了吗。能力复利系数(CCC)关心这次经验有没有让未来任务更便宜。如果一个代码智能体写下一个测试,未来同类故障少跑了十次无效尝试,这就是收益。如果一个浏览器智能体学到一个工作流,但页面一改就误导系统,这个知识产物的维护成本和错误成本可能超过收益。
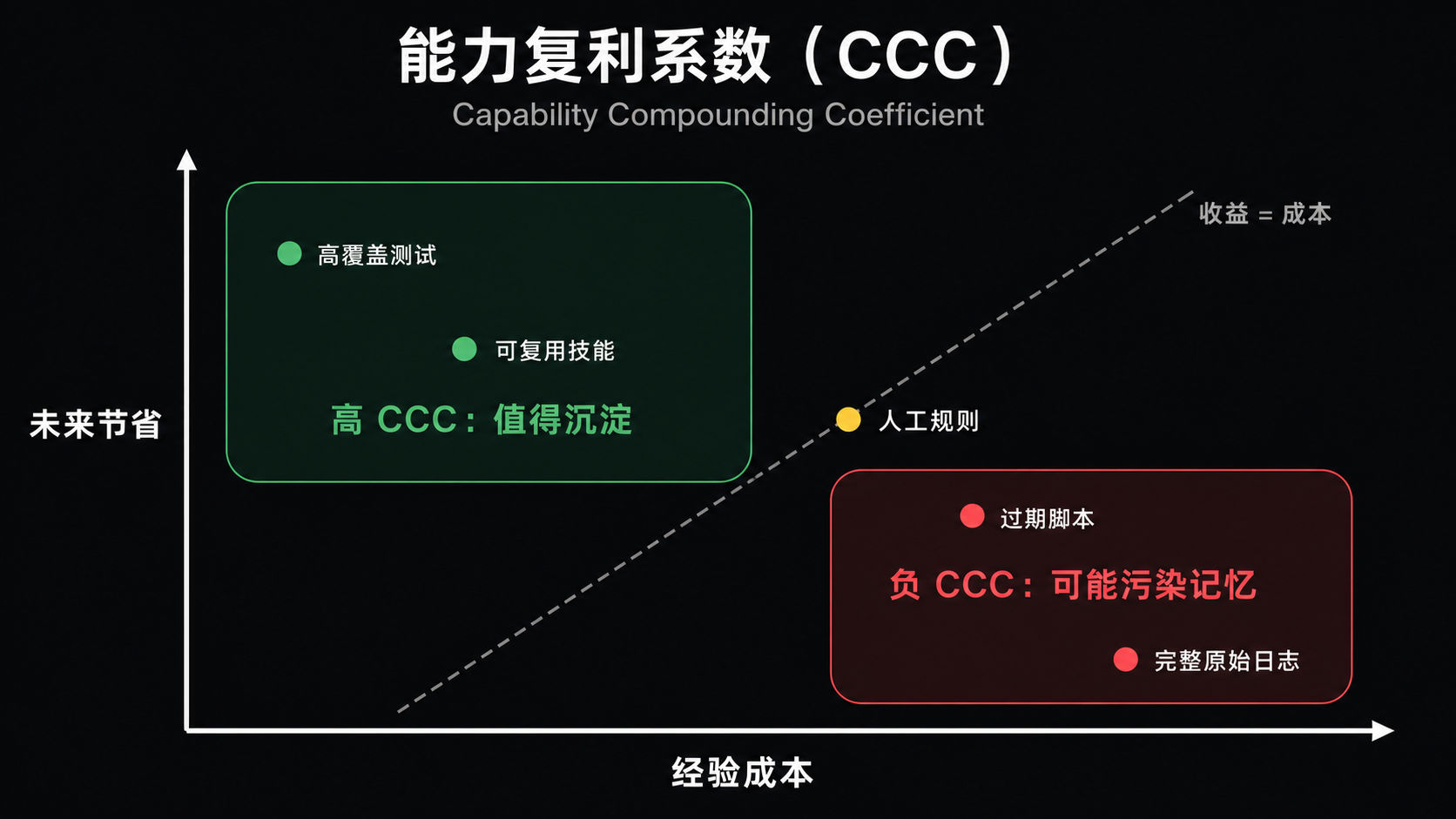
| 能力复利系数(CCC)关注的收益 | 通俗解释 |
|---|---|
| 行动减少 | 下次少点几步、少试几次、少走弯路 |
| 失败减少 | 少重复同类错误 |
| 验证成本下降 | 少跑无用测试,或更快找到关键验证器 |
| 人类接管减少 | 更少需要人来纠偏 |
| 迁移提升 | 换任务、换布局、换环境后仍有帮助 |
| 成功率提升 | 不只是更快,也更稳 |
| 能力复利系数(CCC)也要算的成本 | 通俗解释 |
|---|---|
| 创建成本 | 得到这个经验花了多少交互 |
| 验证成本 | 需要多少测试、评审或验证器 |
| 检索成本 | 未来找到并使用它要花多少时间 |
| 维护成本 | 它过期、冲突、污染时如何处理 |
| 错误成本 | 错用它会造成多少失败 |
能力复利系数(CCC)不是说多存经验总是好。它要求经验被验证、被标注适用范围,并在隐藏任务上真的降低未来成本。一个系统如果只是把所有历史塞回上下文,不一定有正 CCC。那可能只是把垃圾也一起带回来了。
接下来算法上该怎么做
这套思路不要求一上来训练一个巨大的基础世界模型。更实际的路线是做一个主观世界模型适配器:把已有模型、工具、模拟器、智能体运行框架或机器人策略外面包一层可测的判断和控制结构。
换成训练流程的说法:底座模型提供预训练先验,VLA/WAM/工具轨迹提供面向任务的示范学习,W2 Adapter 则负责交互后的信用分配和后训练。它不只是让模型更会模仿正确动作,而是让系统从“预测错了、动作没生效、测试失败、页面过期、物体滑落、实验不支持假设”这些反馈里更新自己的可控状态判断。
这层适配器先做几件朴素但关键的事。它记录当前判断,而不是只保存原始执行记录。它预测动作后果,而不是只执行动作。它估计目标进展和失败风险,而不是只看最终成功。它检查外部记忆和技能是否仍适用于当前状态,而不是盲目复用。它把已验证经验写成带来源、范围和过期条件的知识产物,而不是把所有历史都当成知识。
如果写成工程结构,它大概包括几个头:状态判断、动作后果、失败风险、记忆可信度、经验提炼。它不一定替代基础模型,而是让基础模型的观察、行动和记忆多一层可检查的中间判断。
如果任务进入物理信号或科学发现场景,这层结构还需要显式处理测量可信度和实验干预。它要问:这个读数来自什么仪器,校准是否可靠,时间戳和采样频率是否匹配,哪些变量可以主动改变,哪个实验最能区分两个假设,哪些发现可以写成方程、因果图、验证脚本或实验协议。也就是说,行动不只是完成任务,还可以是检验世界模型的实验。
落到机器人上,这个观点会更具体。不是从零训练一个比 π0 或 WorldVLA 更大的机器人基础模型或视频模型,而是把这些模型当作动作底座、训练信号或强对照组,在它们上方或旁边训练一层主观世界模型。它要预测的不是完整视频,而是更紧凑的行动变量:对象现在处于什么状态,任务走到哪一步,当前身体和物体配置下哪些动作可执行,某个动作会改变什么,失败风险在哪里,失败后应该回滚、重试还是换策略,当前仿真或世界模型在这个场景里有多可信。
验证也不能只看成功率。具身方向至少应该比较几组同预算系统:普通模仿或扩散策略,纯 VLA,纯 WAM,VLA 加任务阶段判断,VLA 加主观世界模型但不复用技能,VLA 加主观世界模型和技能复用,再分别去掉动作后果头或外部知识蒸馏。真正要看的,是换布局、换物体、被遮挡、长程任务、跨机器人身体、仿真到真实迁移时,系统是否少重复失败、少人工接管、恢复更快,并且让后续任务成本下降。LIBERO、RoboCasa 和 BEHAVIOR 这类基准适合做这种阶梯式验证,但只有当它们记录对象状态、任务阶段、失败恢复和复用收益时,才真正变成主观世界模型的检验场。10
同样的结构也适用于代码和浏览器智能体。代码里要记录的是假设、失败命令、测试输出、补丁差异和后续复用;浏览器里要记录的是页面状态、权限变化、按钮是否生效、弹窗和恢复路径。共同点是:训练目标从单次输出正确,转向动作改变了什么、错误如何恢复、经验如何降低未来成本。
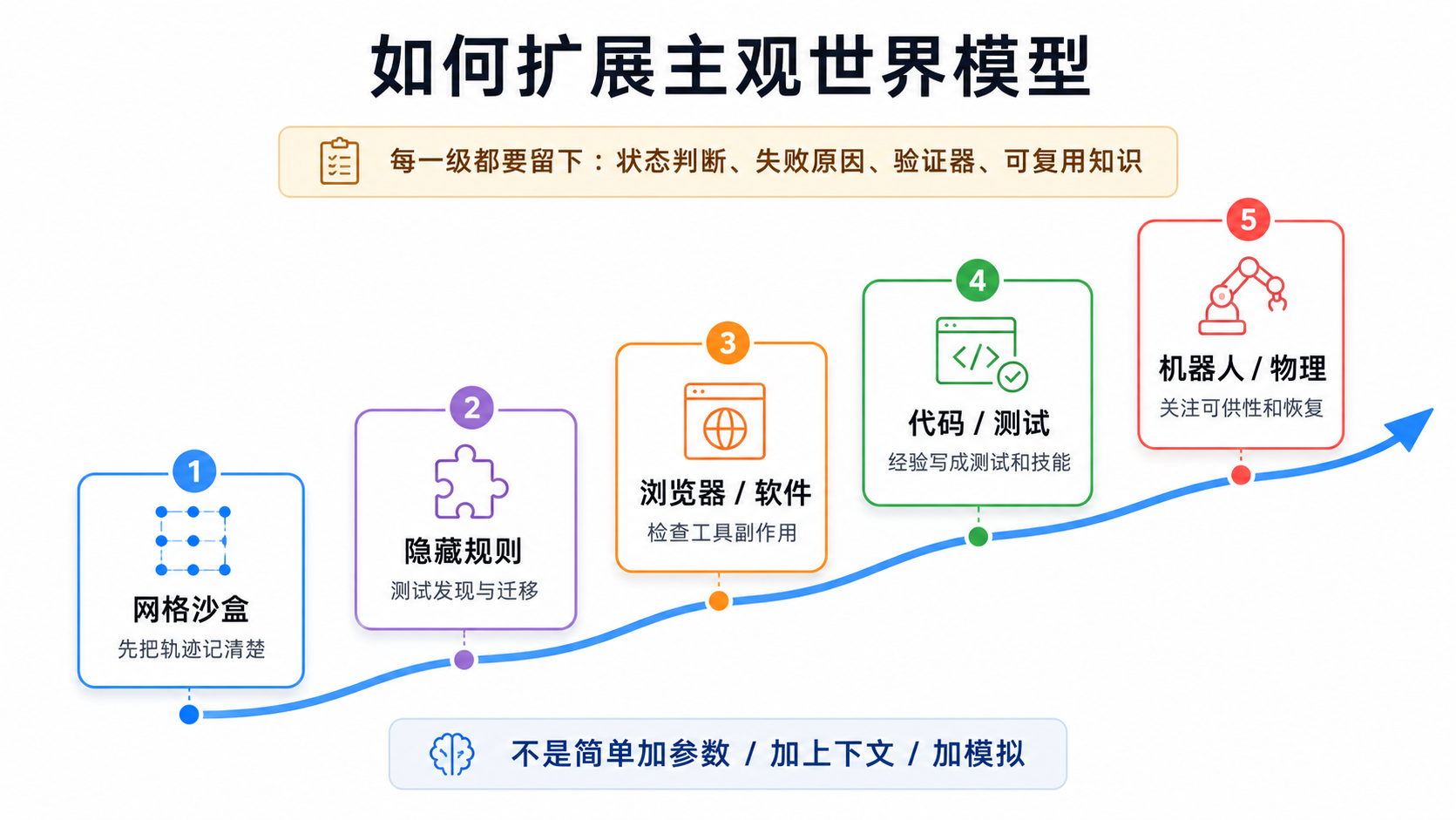
验证顺序也应该从小到大。先在网格世界里把轨迹和对照实验做干净,再做类似 ARC 的隐藏规则任务,测试系统能不能发现隐藏规律并迁移。然后进入数字环境,例如浏览器和软件环境,测试页面状态、工具副作用、权限错误和页面过期。再进入代码和终端任务,看测试、补丁和验证器能不能形成外部知识复用。再往后可以加入小型科学任务:连续时间轨迹、带噪测量、仪器偏差、可干预变量和隐藏动力学。最后才是具身环境,也就是机器人和物理环境里的对象、阶段、可供性和身体状态。9
如何扩展(Scaling):扩大可验证经验循环
这里说的扩展,不只是把模型参数加大、上下文加长,或者模拟器做得更逼真。这些当然有用,但如果系统仍然不知道哪些状态值得保留,哪些经验已经过期,哪些行动会改变结果,那么规模只会把噪声也一起放大。
一个更具体的类比是把下一代行动智能体看成三段训练:
| 类比阶段 | 在具身/视频里的对应物 | 学到什么 | 还缺什么 |
|---|---|---|---|
| 预训练 | VLM、视频模型、物理世界模型、科学 foundation model | 视觉语义、空间结构、物理或科学先验、常见动态 | 不知道当前任务下哪些变量可控、哪些细节值得保留 |
| 指令微调 | VLA、WAM、示范轨迹、工具调用轨迹 | 指令到动作、观察到动作、动作到未来的常见映射 | 容易学成模仿和相关性,不一定知道失败原因和恢复路径 |
| 强化学习式后训练 | W2Trace、验证器、失败恢复、ArtifactStore、CCC | 从交互反馈中学习可控变量、模型可信度、恢复策略和经验复用 | 需要可记录、可回放、可比较的闭环数据 |
这里的“强化学习式”不是说只能用某一种 RL 算法,而是说训练压力来自交互后的结果:预测的动作后果是否发生,目标进展是否变好,失败是否被识别,恢复是否缩短,经验是否降低了未来任务成本。换句话说,W2 需要优化的不是“看起来像专家动作”,而是“同样预算下更少重复失败、更快恢复、更少人工接管、更高隐藏任务复用收益”。
所以在具身方向,扩展不应该只理解成收集更多成功示范或生成更多合成视频。那些当然重要,但更像在扩大预训练和指令微调的数据供给。主观世界模型关心的是另一层扩展:失败类型覆盖是否更广,动作前后对象状态是否更完整,人工接管原因是否被记录,仿真和真实差异是否被校准,成功经验是否能被压缩成带适用范围的技能。机器人数据集如果只越来越大,却不记录这些字段,就更像更大的模仿语料;如果记录了这些字段,才开始变成可训练、可审计、可复利的经验系统。
举一个具体例子。一个视频模型可能知道“杯子被推到桌边后会掉下去”,这是很好的预训练先验。一个 WAM 可能学会“夹爪向杯子移动后,未来画面里杯子会靠近夹爪”,这已经进入动作条件化。W2 还要记录:夹爪是否真的接触杯子,杯子有没有滑动,当前抓取是否可靠,失败是因为遮挡、姿态、摩擦还是力度,下一次应该重试、换抓取点还是先移动障碍物。如果这次失败后来被写成一个检查项或恢复技能,并在新布局里减少重复失败,它才开始产生能力复利。
数字任务也一样。浏览器或代码智能体的“预训练”让它知道网页、代码和测试大概是什么;工具轨迹或示范让它学会点击、编辑、运行命令;W2 后训练要让它学会页面刷新后旧按钮可能失效、某个测试验证的是哪个假设、某个补丁路线为什么失败、哪个经验在当前仓库还能复用。这里的关键数据不是完整聊天记录,而是动作前后状态、预测结果、真实 delta、失败类别、恢复动作和后续复用收益。
同理,科学世界模型的扩展也不应只理解成“喂更多原始信号”。原始信号本身不是现实,它仍然经过传感器、仪器和采样链路。真正有价值的是把校准过的测量、连续时间轨迹、干预记录、不确定性、误差模型和可复验的科学 artifact 放进同一条闭环里。否则系统可能只是从 JPEG 文本世界换到传感器读数世界,并没有学会哪些变量可控、哪些规律可迁移、哪些结论可以被实验推翻。
因此,扩展的对象不是单个内部表征,而是整个后训练闭环:更开放的可交互客观世界、更精准的当前判断、更可靠的外部知识产物、更严格的隐藏任务验证。只有这四件事一起扩展,经验才可能变成能力复利。否则系统可能只是更会想象、更会模仿、更会执行,但不一定更会从失败和复用中学习。
反方观点:也许 W2 会被隐式学出来
这篇文章不是说每个强系统都必须有一个显式模块叫 W2。最强反方很简单:也许参数规模、长上下文、更多交互数据、更强后训练、更大的 WAM,会让模型隐式学到同样功能。
这完全可能。
如果一个没有显式主观世界模型适配器的系统,在相同模型、数据、工具、交互和验证预算下,能匹配显式适配器的恢复能力、迁移能力、外部知识复用能力和隐藏任务上的能力复利,那么显式 W2 就不应该被说成必要。具身方向尤其应该这样检验:如果更大的 WAM 系统,经过同样强度的交互后训练后,能稳定解决遮挡、布局变化、失败恢复、跨机器人迁移、人工接管减少和经验复用,那么主观世界模型适配器的必要性就要被削弱。它也许只是一个分析框架,或者只在某些领域有工程价值。
但如果这些绕过路线在局部任务上成功,却反复出现同类失败,比如相信过期记忆、不能区分相关变量和可控变量、失败后不断重复、经验无法降低未来成本,那么主观世界模型就不只是一个解释标签。它会变成当前系统缺失的接口。
结语:从世界模拟到经验复利
世界模型这个词之所以混乱,是因为它确实覆盖了很多不同实现:强化学习模型、视频生成模型、机器人状态-动作策略、智能体思考、规划、记忆、工具轨迹、测试和技能。把它们放到一个大框架里是有帮助的:它们都在处理未来相关知识。
但下一步问题更窄:有限智能体到底应该保留什么未来知识?三重世界模型给出的回答是,把交互世界、内部判断和外部知识分开看。可交互客观世界提供会响应动作的环境,外部知识世界保存可复用知识产物,而主观世界模型负责在当前目标下选择可控、可恢复、可复用的未来信息。预训练可以提供广泛先验,示范学习可以提供常见动作模式,但长期能力复利还需要一条能从交互、失败、验证和复用中持续更新的后训练闭环。
所以,主观世界模型的价值不在于名字。它的价值在于提出一个可检查的标准:如果没有它的绕过路线也能做到同等预算下的恢复、迁移、知识复用和能力复利,那么显式 W2 不必要;如果做不到,它就是下一代智能体需要补上的关键层。
参考资料
Footnotes
-
Richard S. Sutton, Integrated architectures for learning, planning, and reacting based on approximating dynamic programming, 1990; David Ha and Jürgen Schmidhuber, World Models, 2018; Julian Schrittwieser et al., Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model, 2020; Danijar Hafner et al., Mastering Diverse Domains through World Models, 2023. ↩ ↩2
-
Yann LeCun, A Path Towards Autonomous Machine Intelligence, 2022; Adrien Bardes et al., Revisiting Feature Prediction for Learning Visual Representations from Video, 2024; OpenAI, Video generation models as world simulators, 2024. ↩ ↩2
-
Shunyu Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models, 2022; Noah Shinn et al., Reflexion: Language Agents with Verbal Reinforcement Learning, 2023; Guanzhi Wang et al., Voyager: An Open-Ended Embodied Agent with Large Language Models, 2023. ↩ ↩2
-
《AGI 不该只读文字:从物理信号到科学世界模型》(2026)。 ↩
-
相关一手线索包括 Meta AI, Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning, 2025; Archetype AI, Physical AI / Newton, 2026; Archetype AI, A Phenomenological AI Foundation Model for Physical Signals, 2024; Polymathic AI, AION-1: Omnimodal Foundation Model for Astronomical Sciences, 2025; Yiqi Yang et al., Walrus: A Cross-Domain Foundation Model for Continuum Dynamics, 2025; Steven L. Brunton et al., Discovering Governing Equations from Data, 2015; Bernhard Schölkopf et al., Towards Causal Representation Learning, 2021. 这些材料支持“物理信号、科学结构和因果变量是重要世界模型来源”的背景判断;是否成为 W2 证据仍要看目标条件化、行动干预、可控性和复用验证。 ↩
-
Michael Ahn et al., Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, 2022; Anthony Brohan et al., RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, 2023; Moo Jin Kim et al., OpenVLA: An Open-Source Vision-Language-Action Model, 2024; Kevin Black et al., π0: A Vision-Language-Action Flow Model for General Robot Control, 2024; Jun Cen et al., WorldVLA: Towards Autoregressive Action World Model, 2025. ↩
-
Karl Popper, Three Worlds, Tanner Lecture, University of Michigan, April 7, 1978. ↩
-
Stephen Thornton, Karl Popper, Stanford Encyclopedia of Philosophy. 其中 Objective Knowledge and The Three Worlds Ontology 小节概述了 Popper 的 World 1、World 2、World 3 划分。 ↩
-
François Chollet et al., ARC-AGI-3 Technical Report, 2026; Tianbao Xie et al., OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, 2024; Carlos E. Jimenez et al., SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, 2023. ↩ ↩2
-
Bo Liu et al., LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning, 2023; Soroush Nasiriany et al., RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots, 2024; Chengshu Li et al., BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation, 2024. ↩