大语言模型智能体到底在什么环境里学习?
从给定外部环境,到运行时构造的大语言环境
先从一个很普通的场景说起。一个代码智能体接手陌生仓库,读 issue、改文件、跑测试,最后失败了。失败并不稀奇,真正重要的问题是:第二次遇到同类仓库时,它能不能少走弯路?它应该记住错误栈,记住某个仓库的特殊配置,抽象出一套调试流程,还是把这次经验写进训练数据甚至模型权重?
这个问题比要不要用强化学习更靠前。大语言模型智能体确实需要从自己的行动、失败、修正和验证中继续变好。Sutton and Barto 的经典强化学习框架强调,智能体通过与环境交互、接收后果反馈来改善未来决策(Sutton and Barto, 2018)。Silver and Sutton 把这个判断推进为一个更激进的研究纲领:下一代智能体的能力增长,将越来越依赖持续交互产生的经验流,而不只是依赖静态人类语料(Silver and Sutton, 2025)。
但共识很容易跳得太快。很多讨论一上来就问该不该用 GRPO、PPO,或者能不能把工具调用日志直接写成轨迹后训练。GRPO/PPO 可以是后端优化器代表,却不是本文的起点。强化学习也许是答案的一部分;如果强化学习是答案,我们先要问清楚:它到底在什么环境里学习。
本文的主线分四步。第一步,说明为什么智能体学习首先是环境接口设计问题。第二步,给出大语言环境的工作定义。第三步,解释这个定义如何改写强化学习里的状态、动作、反馈和更新对象。第四步,讨论怎样把一次任务里的日志变成可验证、可迁移、可撤销的经验飞轮。
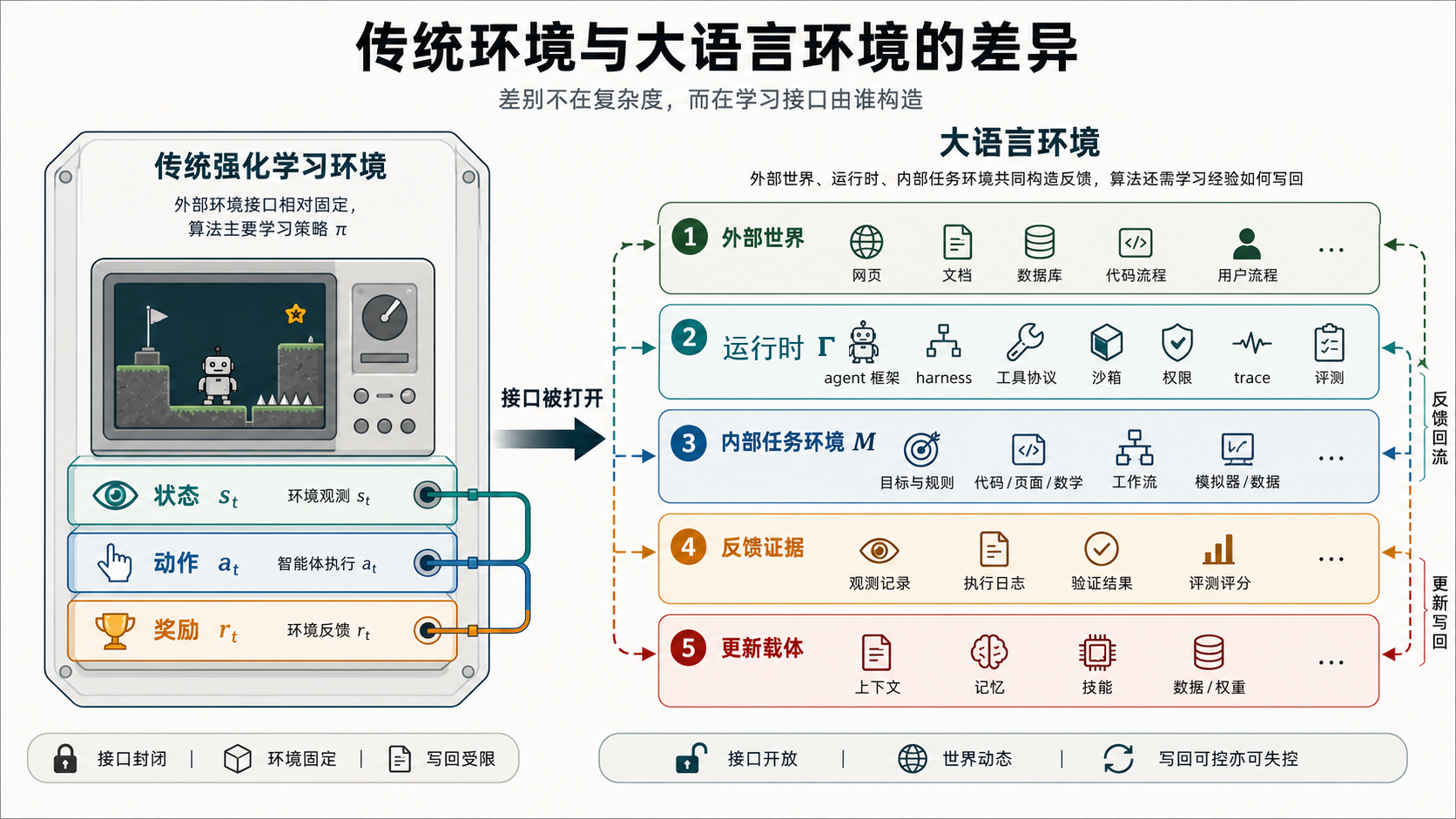
图 1 先给出核心对比。围棋、星际争霸、王者荣耀这类传统强化学习环境当然也可能非常复杂。游戏引擎或模拟器本身就是一种环境,只是它们通常有一个相对明确的外部环境接口:观测怎样给出,动作空间有哪些,环境转移怎样发生,胜负、分数或任务奖励怎样计算。大语言环境的难点不是外部世界更复杂这么简单,而是状态、动作、反馈和更新对象都要经过语言运行时、工具、记忆、验证器和模型内部任务环境共同构造。
这也能帮助我们理解现在大模型的长思考和规划。很多长思考能力,本质上是在模型已经大致理解任务环境之后展开更长搜索:它知道哪些对象存在,哪些约束不能违反,哪些中间步骤可以检查,最终答案可以被什么依据验证。数学题里,验证依据可能是形式推导和最终等式;代码题里,验证依据可能是测试、编译和错误复现;网页任务里,验证依据可能是页面状态和用户目标。长思考解决的是在一个已经比较清楚的内部任务环境里怎样搜索。大语言环境中的强化学习要再往前问一步:这个内部任务环境从哪里来,错了怎么办,能不能被真实交互证据修正、记住和复用。
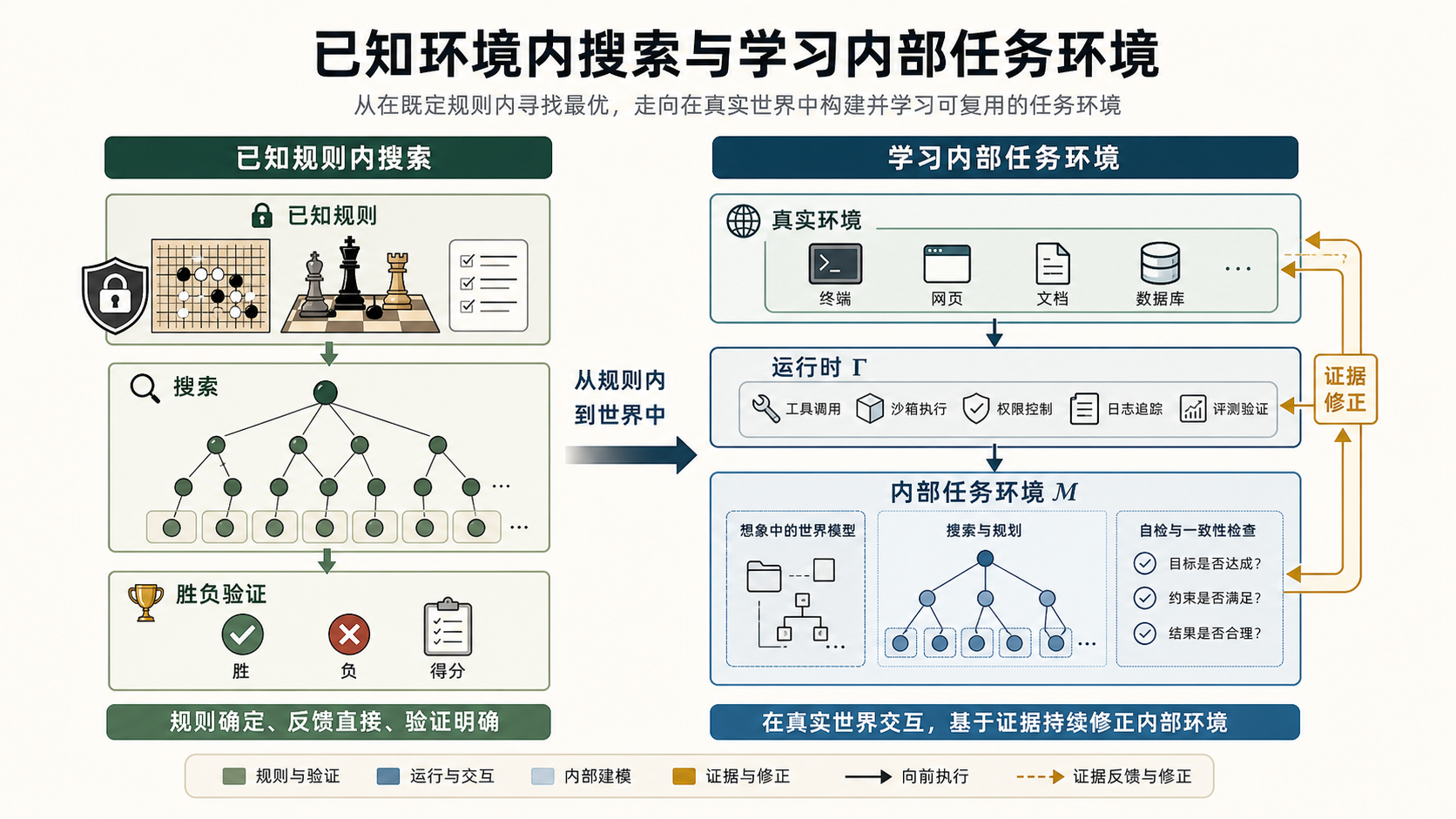
图 2 用围棋和象棋里的蒙特卡洛树搜索做类比。传统搜索之所以有效,通常依赖一个已知或可查询的精确环境:规则已知,状态转移可以模拟,胜负可以验证。大语言环境里的长思考、规划和自我验证也会先在内部展开,但它依赖的是模型对真实外部世界和运行时的近似想象。下文把这个近似称为内部任务环境;在更技术的语境里,它也常被称为世界模型。它不是外部环境本身,而是模型用来预测行动后果、检查计划、生成下一步动作的内部替身。
一、先把问题问清楚:我们其实在设计学习环境
大模型最初的能力飞跃主要来自静态数据扩展。更多文本、更多代码、更大模型、更大训练预算,让模型获得了广泛的语言、代码和推理先验。这个阶段的核心问题是:怎样从已有数据中学习一般能力。
智能体时代的问题不一样。一个智能体不是只回答问题,它会行动。它会打开文件、运行命令、点击网页、调用接口、写代码、等待测试、接收审查意见、读取日志、记住用户偏好、复用过去流程。它的能力不只来自训练前读过什么,也来自部署后经历了什么。
所以这一章的重点不是马上讨论某个优化器,而是讨论学习环境怎样被设计出来。还是用代码智能体做主例:它第一次修复陌生仓库失败,失败原因可能是没有看到关键配置,也可能是动作没有真正落地,也可能是测试证据不充分,还可能是它把一次临时用户偏好误当成长期规则。每一种失败,对应的学习位置都不同。
如果问题是没有看到关键配置,要改的是观测构造。如果问题是模型以为自己改了文件,但运行时没有写入权限,要改的是动作落地。如果问题是测试只覆盖了表面路径,要改的是反馈证据和验证预算。如果问题是把局部经验写成通用技能,要改的是更新路由。换句话说,智能体学习不是把一串日志塞进训练算法就结束,而是要先设计状态、动作、反馈和更新载体之间的接口。
标准强化学习通常从一个已经规定好接口的外部环境开始:智能体接收什么观测,能执行什么动作,什么反馈算奖励,什么时候一轮任务结束。传统强化学习当然也研究过部分可观测、状态抽象、层次动作、奖励学习和非平稳环境。大语言环境的新点不在于这些问题消失,而在于外部世界通过语言运行时、工具、记忆、权限、验证器和内部任务环境被中介之后,接口本身也成了学习系统要定义、校准和治理的对象。
因此,更合适的起点不是先选训练技巧,而是先定义智能体学习的环境:它能看见什么,能影响什么,反馈从哪里来,哪些经验能被写入未来系统,哪些经验必须留在当前任务里。
二、先给定义:大语言环境由五个接口组成
先说结论。大语言环境不是一个单独的模拟器,而是外部世界 + 运行时 + 内部任务环境 + 反馈证据 + 更新载体共同组成的学习场。用符号写就是:
读这个公式时,可以先不管字母,记住一张白话地图:
| 组成 | 直观含义 | 代码智能体里的例子 |
|---|---|---|
| 外部世界 | 真正会被改变的对象 | 仓库文件、依赖、终端、测试环境、issue |
| 运行时 | 把外部世界暴露给模型的中介层 | 智能体框架、执行运行时、任务Harness、工具界面、权限、沙箱、轨迹记录 |
| 内部任务环境 | 模型用来规划和预测的内部空间 | 对代码结构、bug 位置、测试后果的假设 |
| 反馈证据 | 行动后得到的可校准信号 | 编译结果、单测失败、错误栈、审查意见 |
| 更新载体 | 经验最终写入的位置 | 当前上下文、项目规则、记忆、技能、数据、权重 |
是外部构造环境。它包括代码库、网页、文件系统、终端、接口、图形界面、用户和组织流程。它不是纯文本环境,真正的效果仍然发生在外部世界:文件被改了,测试通过了,网页状态变了,日历邀请发出了,权限被触发了。
是运行时环境。它既不是外部世界本身,也不是模型权重,而是把外部世界变成模型可见、可操作、可反馈对象的中介层。两个模型权重完全相同的智能体,只要运行时不同,就可能面对完全不同的学习问题。一个运行时能看到完整错误栈,另一个只能看到测试失败;一个可以执行命令,另一个没有终端权限;一个有项目记忆,另一个每轮清空。
从工程上看, 更接近智能体的执行接口层,而不是某一个具体的智能体框架或评测脚本。现有工程材料通常会把这层拆得更细。第一类是智能体框架,它提供模型、工具、消息、结构化输出和循环控制等抽象,帮助开发者把语言模型接成可运行的智能体;交接、防护、会话和追踪等能力可以由框架提供,但不是所有框架都会以同一种方式提供。第二类是执行运行时,它负责长任务里的状态保存、恢复、流式执行、人类介入和持久化;LangGraph 文档就把这类能力归到运行时层。第三类是智能体Harness:通常是在框架和运行时之上再加一层更有主张的封装,预置计划、子智能体、文件系统、上下文压缩和长任务管理。
因此,当这些Harness参与一次交互轨迹的观测构造、动作落地、环境重置和证据返回时,它们应该纳入 ;如果它们只在任务结束后离线判分,则更接近 或 所代表的证据与验证通道。训练如果忽略这层,就会发生运行时错配:模型学到的可能是如何写出看起来像解决方案的文本,而不是如何在特定运行时里可靠地观察、行动、改变外部世界并通过验证。所以,大语言环境里的 不只是把工具接到模型上的胶水,而是决定状态、动作、反馈和经验边界的核心接口。
是内部任务环境。它包括上下文窗口、系统指令、检索到的记忆、当前计划、候选推理路径,也包括模型在长思考和规划中使用的内部世界模型。这里的内部任务环境不一定只是对外部工具世界的近似。它也可以是模型学到的数学空间、证明空间、代码抽象空间、法律规则空间或组织流程空间:里面有对象、约束、可执行的推理变换、局部验证依据和失败模式。
数学任务能说明这一点。数学题通常没有像围棋引擎那样可查询的外部环境。题目给出的是符号、定义和约束,最终答案也许可以被人类、形式验证器或标准答案检查。但模型真正尝试的地方,是它内部学到的数学空间:哪些变形合法,哪些引理可能有用,哪些中间式子可验证,哪些路径会走向矛盾。强化学习如果只把数学看成问题输入和最终答案奖励,就会漏掉最关键的对象:模型内部那个可搜索、可自检、会出错、也可以被反馈修正的语言化数学环境。
是反馈证据空间,包含测试、编译、环境状态变化、用户纠正、审查意见、安全规则、模型评判和私有评测等信号。 是可更新载体,包括当前上下文、短期记忆、长期记忆、项目规则、技能、验证器样例、数据资产和模型权重。
这个定义和围棋、星际争霸、王者荣耀这类环境的差别,不在于后者简单。星际争霸和王者荣耀的状态空间、动作空间、多智能体博弈都很复杂。但它们通常仍然由游戏引擎给出一个外部环境接口:观测怎样产生,动作是否合法,转移如何执行,胜负或分数如何返回。大语言环境里,观测、动作、反馈和更新对象要由 、、、、 一起构造。
从持续学习角度,还可以把整个大语言环境看作一个持续存在的大世界,或者说一个环境族。每次具体任务不是凭空出现的孤立环境,而是运行时从这个大世界中切出的一个小世界:一个代码修复小世界、一个网页预订小世界、一个数学证明小世界、一个办公审批小世界。小世界有自己的目标、可见上下文、工具权限、局部验证方式和内部任务环境;大世界则保留跨任务共享的工具生态、记忆、技能、验证器、组织规则和模型权重。
这个层次很重要。持续强化学习不是在单个任务里无限试错,而是在许多小世界之间判断哪些经验可以回写到大世界,哪些经验只应该留在当前任务里。一次仓库特殊配置可能只属于当前项目;一种可靠的错误复现流程却可能成为跨仓库技能。定义大语言环境,就是为了让系统有能力区分这两者。
Hint:先定义环境,再谈强化学习。 对大语言模型智能体来说,环境定义至少要说清楚三件事:外部世界有哪些可操作对象,运行时怎样把它们暴露给模型,模型内部用于长思考、规划和自我验证的任务环境从哪里来、怎样被证据修正和更新。
三、大语言环境下强化学习与经典强化学习的三个不同点
经典强化学习的核心仍然有效:智能体行动,环境给出反馈,智能体用经验改善未来行为。问题不在于这个核心过时,而在于很多传统设定会把环境接口先封装好,再在这个封闭接口里优化策略。这样做非常强大,但也容易让研究问题变成一种闭关锁国的优化:外部世界怎样被看见、动作怎样真正落地、反馈怎样被验证、经验怎样影响未来系统,都被压扁成已经给定的状态、动作和奖励。
对大语言模型智能体来说,这个压扁会出问题。外部世界不是一个简单的状态张量,运行时不是透明的空气,模型内部的任务环境也不是永远可靠的。一个代码智能体说我已经修复了 bug,这句话本身不等于外部文件真的被正确修改;一个网页智能体计划点击按钮,也不等于运行时已经找到正确元素并触发页面变化;一个数学智能体觉得证明成立,也不等于每一步变形都有合法依据。
因此,大语言环境下的强化学习至少要拆成三层来看。
第一是表示层。传统环境通常直接给出状态或观测,动作空间也常常有清楚边界。大语言环境里的状态、观测和动作更大、更稀疏、更模糊。一次代码任务的状态可能分散在需求、仓库、依赖、错误栈、测试结果、项目规范和历史修改里;一次网页任务的状态可能分散在截图、DOM、登录态、页面跳转和用户目标里;一次数学任务的状态则分散在题目条件、符号关系、已知定理、候选中间式和证明目标里。表示层要回答:当前小世界里什么应该被看见,什么应该被抽象,什么必须作为后续验证证据保留。
第二是交互层。大语言模型智能体同时和外部世界、运行时以及内部任务环境交互。外部交互发生在代码库、网页、终端、文件、接口和人类组织流程里;内部交互发生在模型的数学空间、证明空间、代码抽象空间、计划树和自我验证过程中。模型的内部推理步骤、外部动作请求、运行时执行和真实环境效果不是同一个东西。智能体框架决定模型怎样组织消息、生成请求、调用工具和切换角色;执行运行时与任务Harness决定请求是否真的执行、执行到什么外部状态、证据怎样返回。训练时如果不拆开,系统只知道任务失败了,却不知道该改观察、改内部任务环境、改工具参数、改权限,还是改动作落地方式。
第三是耦合层。在大语言环境里,同一个大语言模型往往同时承担策略、内部世界模型、奖励或价值判断三种角色。它一方面提出行动,另一方面在内部任务环境里预测行动后果,还可能评价答案、做自我验证、总结经验。于是一次训练或一次记忆更新,改变的可能不只是策略 ,也可能同时改变内部任务环境 和价值/奖励判断 。系统可能因为更新策略而改变了自我验证标准,也可能因为更新记忆而改变了内部世界模型,还可能因为模型评判器和策略模型共享偏差而形成自我确认。
这三层不是为了把文章讲复杂,而是为了避免三类常见误判:把日志误当成经验,把反馈误当成奖励,把局部成功误写成全局能力。日志只有经过任务边界、动作落地、证据验证和更新路由之后,才可能成为经验;反馈只有带上来源、作用范围和锚点强度之后,才适合被解释为奖励、偏好或约束;一次小世界里的成功,只有经过跨任务复现和风险检查,才适合回写到更大的系统。
所以,问题不是传统强化学习是否还有用。问题是传统设定中通常先被稳定下来的状态、动作、奖励和更新对象,在大语言模型智能体里被重新打开了。强化学习不能只问怎样优化策略,还要问状态和动作怎样表示,内外环境怎样交互,策略、内部环境模型和价值判断怎样共同被更新而不相互污染;也要问小世界里的经验怎样被筛选、抽象和回写,才能让整个大世界越用越可靠。
四、形式化:算法到底该学什么
前面的大语言环境定义回答的是环境是什么。这里的形式化回答另一个问题:在这个环境里,算法到底要学什么。结论先说:大语言环境中的算法不应该直接学习日志,而应该学习经过观测构造、动作落地、证据验证和更新路由之后的经验对象。
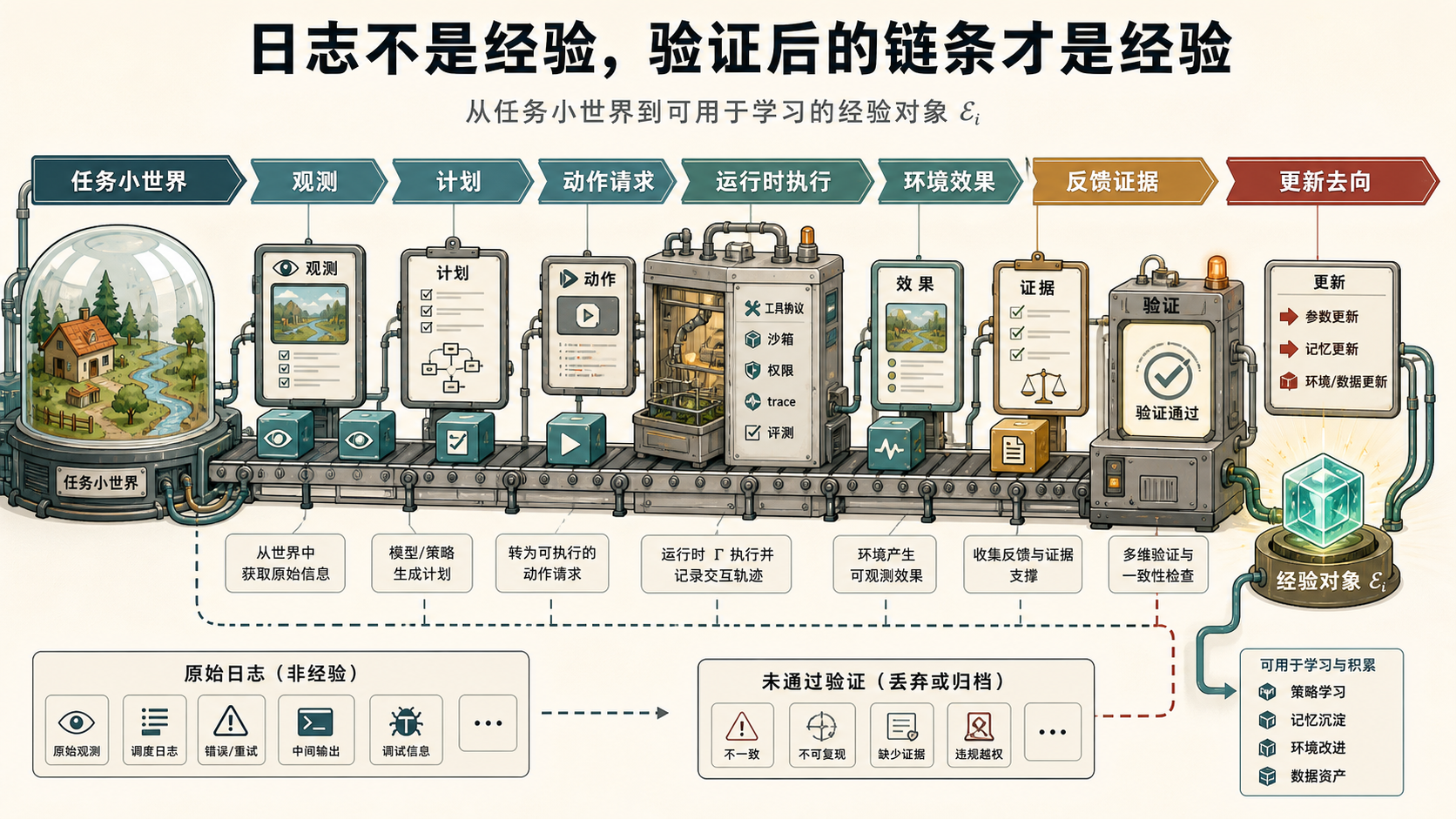
图 3 把这一节的核心对象画出来:一次任务小世界 里的原始日志,只有经过观测、计划、请求、执行、环境效果、证据和验证这些环节,才会成为可学习的经验集合 。随后,更新路由 决定它留在当前上下文、进入记忆和规则,还是进一步沉淀为技能、数据或权重。
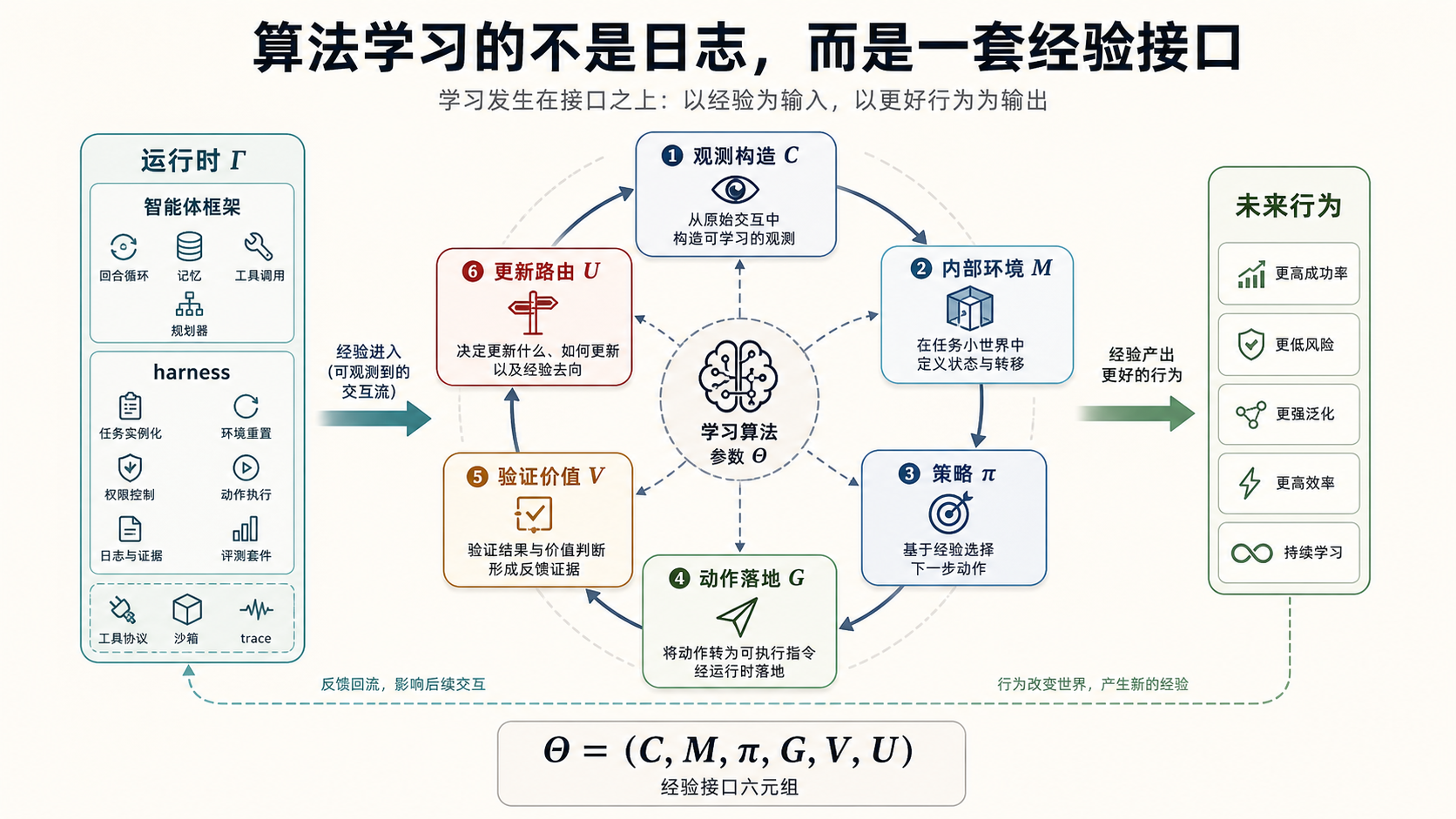
图 4 用更直观的方式表达同一件事。算法不是从左到右吃一条原始聊天记录,而是吃一个被构造出来的接口:运行时决定模型看见什么,内部任务环境帮助模型规划和预测,动作落地层把请求变成真实效果,反馈证据层判断结果是否可靠,更新路由再决定这条经验影响当前上下文、项目记忆、技能、数据还是权重。
在传统强化学习里,我们常常问:在一个给定环境里,怎样学习从状态到动作的策略,让长期奖励更高。如果只从最抽象的层面看,大语言环境中的强化学习当然也没有脱离这个精神:它也希望经验让未来表现更好。真正的区别在下一层:传统写法通常把环境、状态、动作、奖励和更新对象先固定住,然后优化策略;大语言环境的问题是,这些接口本身还在被构造和校准,我们可以先简单地把接口划分为以下几类:
其中 负责把历史、工具输出、记忆和规则构造成观测, 是用于长思考、规划和自我验证的内部任务环境, 负责提出内部思考动作和外部动作请求, 负责把外部请求落地成真实动作, 泛指验证器、奖励/价值模型和偏好判断,负责把反馈证据转成验证、奖励、偏好或约束, 负责决定经验写到上下文、记忆、技能、数据还是权重。
传统强化学习主要问在给定环境里怎样学 。大语言环境强化学习还要问 怎样一起被学习和治理。更麻烦的是,在真实系统里 往往并不是三个完全独立的模块,而是同一个大模型在不同角色下的表现;所以更新策略时,也可能同时改变内部任务环境和价值判断。
如果暂时把持续学习也纳入这套记号,可以把一个任务小世界中积累的经验集合记作 。但这里不必急着把它写成一个严格的优化目标,因为未来行为改善更新风险验证成本和经验可迁移性现在还很难被一个可靠的标量函数同时表达。更稳妥的说法是:持续学习要研究的是, 中哪些经验只适用于当前小世界,哪些可以进入项目记忆或技能库,哪些需要更多验证后才能进入数据资产或权重。
所以,这里的形式化先提供研究方向,而不是给出最终目标函数。它把问题从怎样最大化当前任务得分扩展到怎样产生可学习经验、怎样解释证据、怎样控制更新范围。一个任务成功但污染了长期记忆,不算真正学好;一个任务失败但留下了可靠证据、失败归因和可撤销规则,反而可能提升未来同类任务。
如果继续用代码智能体做例子,一条可学习经验至少要说明:这次任务来自哪个仓库小世界,模型当时看到了哪些文件和错误,内部计划是什么,提出了什么修改请求,运行时实际改了哪些文件,测试或审查给了什么证据,验证强度有多高,最后这条经验被写到了哪里。符号可以很复杂,但要点很简单:经验对象必须把任务边界、表示、内部任务环境、计划、行动、外部效果、证据、验证和更新放在同一个链条里。
在这里,几个容易混用的概念需要分清楚。反馈是行动之后系统收到的原始信号,例如错误栈、测试结果、页面状态、人类评论或安全报警。证据是带有来源、作用范围、置信度和风险标签的反馈。锚点是相对独立、可以校准证据的机制,例如编译器、单元测试、真实网页状态、形式规则、人类专家、私有评测或制度规则。验证是用锚点检查候选行动、结果或整条轨迹是否可靠。奖励则是把证据投影成可优化信号之后的结果,可以是标量分数、偏好比较、约束、拒绝更新标记或训练样本。
在理想强化学习设定里,如果环境、目标和奖励函数都被清晰定义,标量奖励可以承载足够信息,这与奖励足够论在概念上并不矛盾(Silver et al., 2021)。本文不是反对奖励最大化,而是主张在 LLM agent 的工程环境里,奖励通常应当是证据对象被解释、校准和路由之后的产物。一次编译失败告诉你语法位置,一次单测失败告诉你行为偏差,一条审查意见告诉你项目规范,一次用户纠正告诉你偏好或误解,一次安全报警告诉你某条路径不能被学习。过早把这些反馈压成一个分数,会丢掉最有用的学习结构。
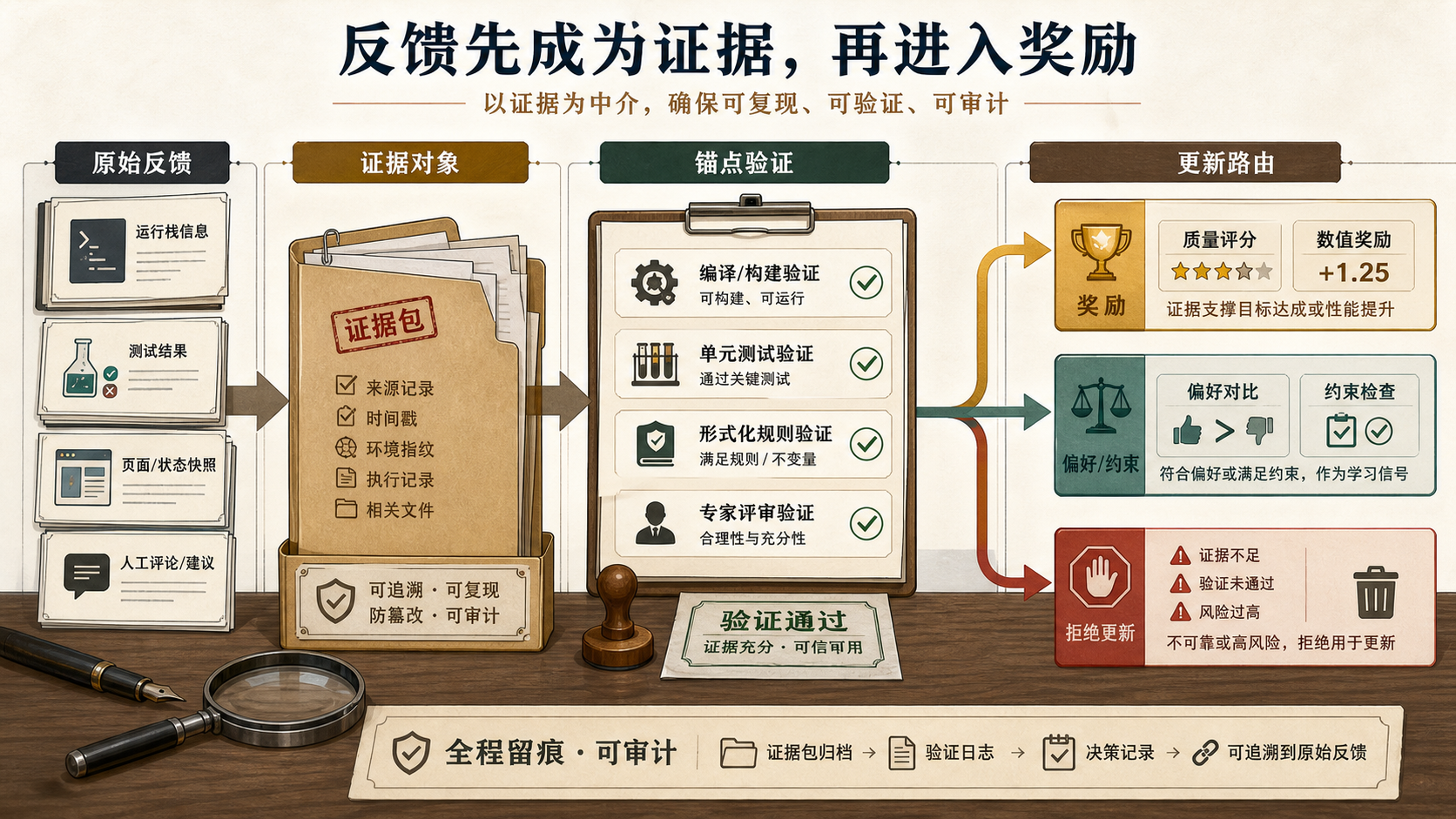
图 5 的重点是:奖励形式本身没有问题,问题是奖励不能在证据被理解之前先行。过程监督和验证器研究已经说明,中间步骤、最终答案、测试和判分器携带的证据强度并不相同(Lightman et al., 2023)。大语言环境中的算法目标,不只是最大化当前任务得分,而是让系统学会三件事:在表示层产生可学习经验,在交互层判断证据和信用归因,在耦合层决定奖励/价值判断与更新去向。
因此,经验应该写到哪里不是后处理问题,而是学习目标的一部分。前面 里的 不是普通日志系统,而是持续强化学习的更新路由器。它要判断一条经验适合留在当前上下文,还是进入短期记忆、项目规则、技能候选、训练数据,或者最终影响模型权重。没有 ,强化学习就只剩下当前任务得分;有了 ,系统才开始真正回答如何让一个小世界中的可靠经验改善未来小世界。
这也解释了为什么持续强化学习不是可选增强。更强模型当然有帮助,但更强模型不会自动解决经验治理。模型越强,越能行动;越能行动,错误经验的影响范围越大。一个强模型如果把公开评测技巧记成通用能力,把一次性用户偏好写成长期规则,把危险工具调用封装成技能,把自己生成的低质量数据重新吃回训练集,它造成的问题也会更大。模型坍缩相关研究提醒我们,问题不在于合成数据一概不能用,而在于递归生成数据如果没有来源标记、真实数据混合、多样性维护和评测隔离,会把错误分布持续放大(Shumailov et al., 2024)。
另一个原因是,未来很多重要信息都不在预训练数据里。企业内部代码库、用户长期偏好、实时网页、私有工具、项目历史、组织流程,这些都只能在部署后交互中获得。智能体必须在使用中学习。问题不是它能不能短期适应,而是这种适应能不能被验证、抽象、复用和撤销。
这就引出一个关键原则:权重应该放在最后。权重更新不是不能做,而是证据门槛最高、撤销成本最高、影响范围最大。一次错误经验如果只停留在当前上下文,任务结束后就消失。如果写入长期记忆,会影响未来相关任务。如果变成技能,可能被自动复用。如果进入训练数据或权重,会扩散到更大范围,而且更难撤销。
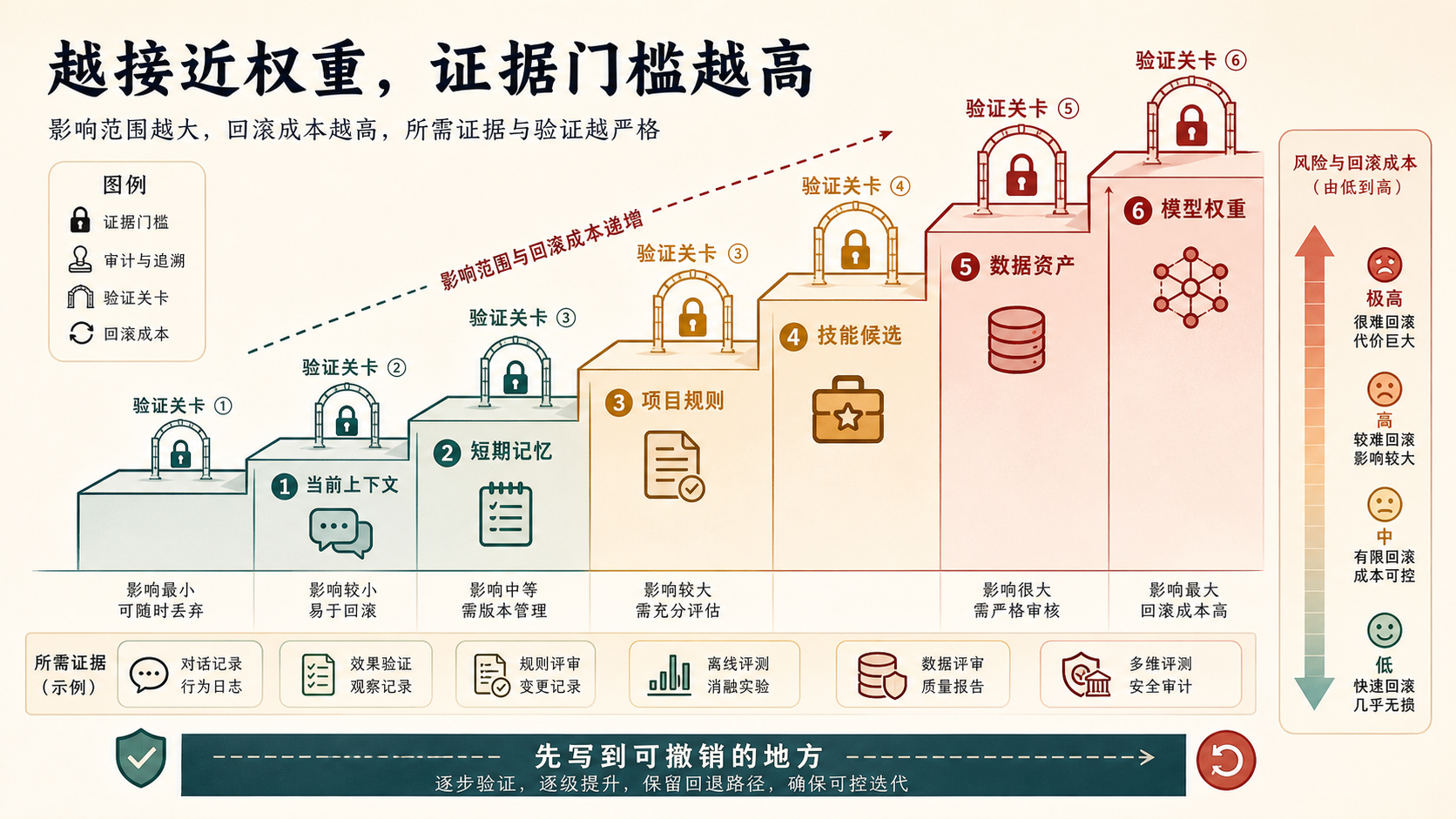
图 6 表达的是更新载体的风险梯度。经验越接近模型权重,影响范围越大、撤销越难,所以需要更强验证。前面讨论的是证据是否可信;更新路由讨论的是可信到什么程度才允许进入不同载体。没有这层路由,智能体就会把发生过的东西误当成应该学习的东西。
Hint:先写到可撤销的地方。 一次新经验可以先进入当前上下文、短期记忆、项目规则或技能候选;只有经过跨任务复现、独立验证和安全检查后,才适合沉淀为数据资产或权重更新。对大语言环境来说,持续学习首先是更新路由问题,其次才是参数更新问题。
所以,更准确的说法是:高层目标仍然是未来回报或未来行为改善;本质差异在于,传统设定通常优化固定环境中的策略,而大语言环境还要优化经验生成、证据解释和更新路由这套机制。一个系统如果当前任务分数更高,但把一次性偏好写进长期记忆,把弱模型评分当成硬奖励,把错误工具使用沉淀成技能,它并没有真正学好。反过来,一个系统即使某次任务失败了,只要它保留了正确证据、完成了失败归因、更新了可撤销的项目规则,未来同类任务表现可能会变好,这条经验就是可学习的。
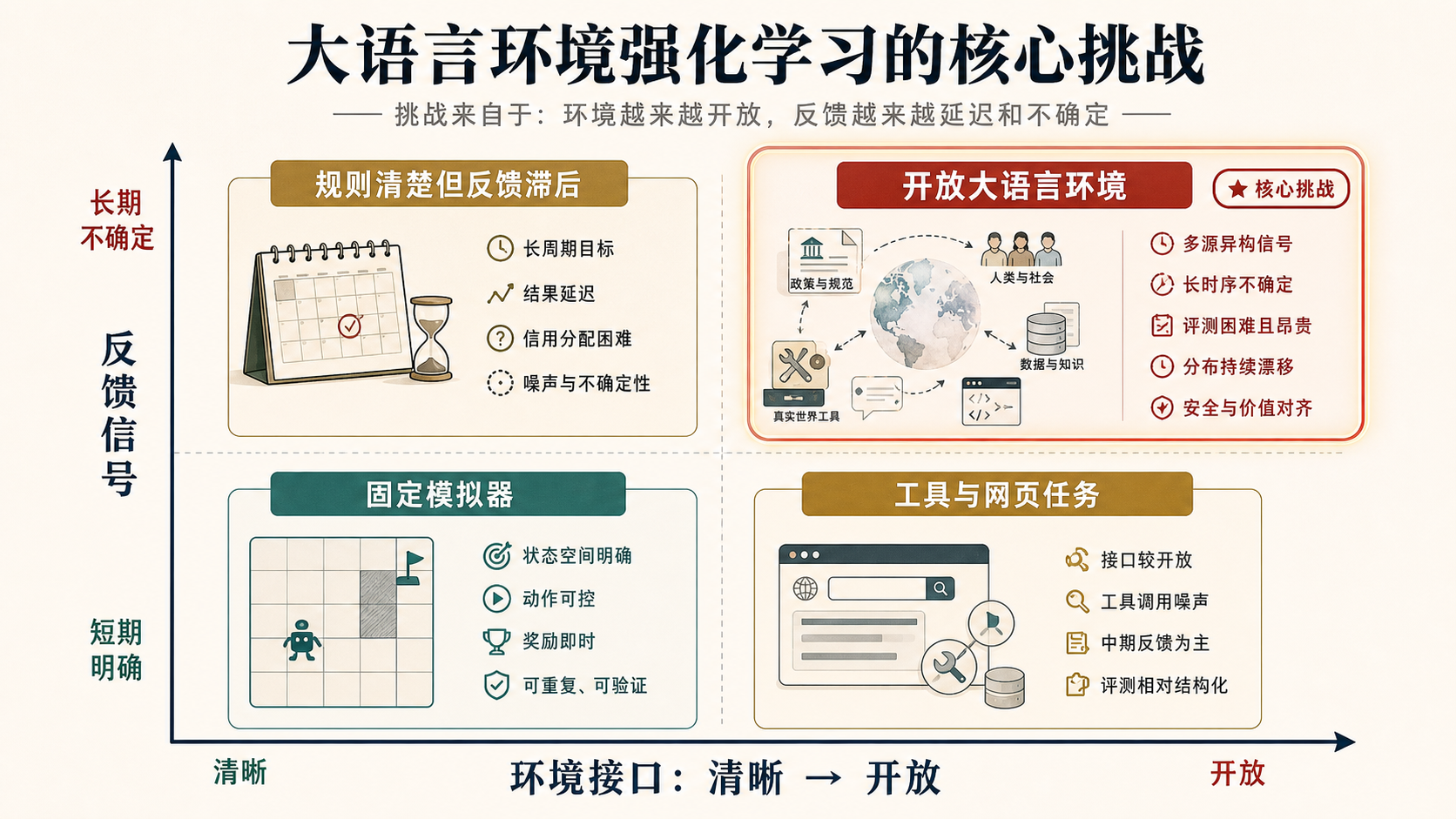
图 7 用坐标图概括这个目标。横轴不是单纯环境复杂度,而是环境定义的清晰程度:左边是清晰模拟器和固定规则,右边是真实工具、网页和组织流程这类开放模糊环境。纵轴也不只是验证难度,而是反馈信号的时间尺度和确定性:下方是胜负、测试、即时奖励这类规则明确的短期反馈,上方是长期效果、安全和人类价值这类更不确定的反馈。大语言环境强化学习的目标不是把问题推向右上角,而是在右上这类开放场景中构造可学习经验接口。
Hint:先找可靠锚点。 训练代码智能体时,可以优先利用编译、测试、静态检查、代码审查和缺陷复现;训练网页和界面智能体时,要记录页面状态、点击目标、网络结果和任务完成证据;训练办公智能体时,要把权限、审批、人类确认、组织规则和偏好作用范围纳入反馈;训练数据分析智能体时,要保留数据版本、清洗步骤、图表结果、统计假设和复现实验。领域不同,经验轨迹、验证预算和更新路由也应该不同。
五、规模化:持续经验飞轮
这一节只讨论大语言环境中的经验扩展,而不是物理世界或机器人系统里的经验扩展。物理世界当然也需要从经验中学习,但它面对的是传感器、物理动力学、身体控制、硬件磨损和现实安全约束。大语言环境的核心对象不同:语言上下文、工具调用、文件状态、网页状态、记忆、验证器、人类反馈和组织权限。
谈到规模化,大家最熟悉的是预训练时代的路径:更多数据、更大模型、更多算力。这个路径仍然重要,但它主要回答的是静态语料如何转化为模型参数中的先验。大语言环境中的规模化要回答另一个问题:真实语言和工具交互产生的经验,怎样从一次性的任务痕迹,变成可以持续生产、验证、复用和治理的能力来源。
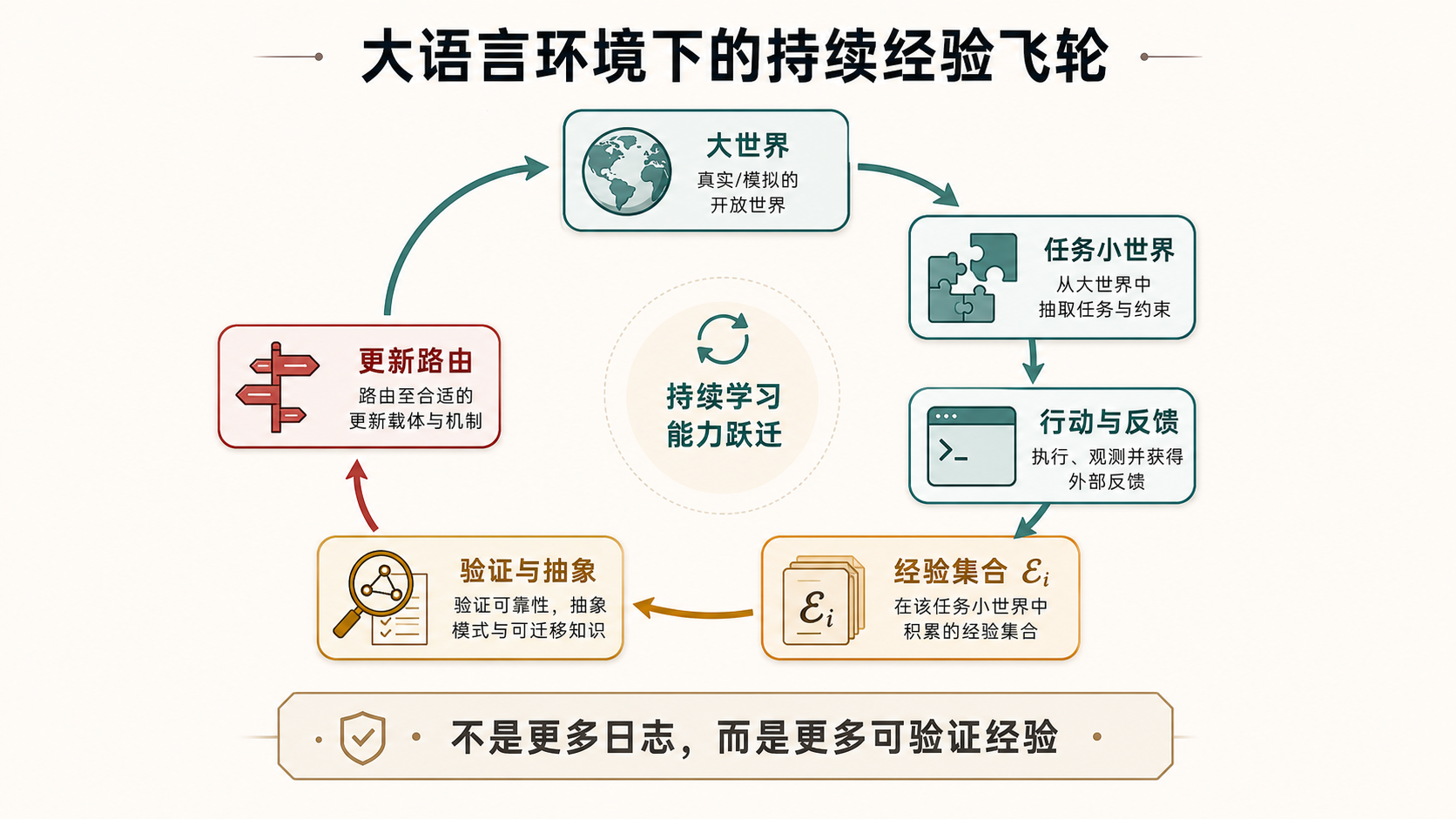
图 8 把大语言环境下的经验扩展定义为一个闭环。大世界不断实例化出新的任务小世界;智能体在小世界里观察、长思考、行动、接收反馈;系统把轨迹整理成经验对象,经过验证和信用归因之后,再由更新路由决定写回哪里。写回之后的大世界会影响下一批小世界如何被构造。规模化目标不是更多日志,而是这个闭环能稳定产生更多被验证、可迁移、可撤销的经验。
用大世界和小世界的说法,经验飞轮的输入是一个个任务小世界里的 ,输出不是把所有轨迹混进同一个训练池,而是把经验分流到合适的位置。局部经验留在局部小世界,项目经验进入项目记忆或规则,可迁移技能进入技能库,跨领域稳定经验才可能进入数据资产或权重。持续强化学习要规模化,核心不是让模型在同一个任务上反复刷分,而是让许多小世界中的可靠经验共同改善大世界的构造方式。
这意味着规模化不能只看轨迹数量。一个系统每天产生一百万条工具调用日志,如果其中大部分没有可靠验证、没有清楚归因、没有来源记录、不能复用,也不能撤销,那么它不是大语言环境下的经验扩展,而是日志扩展。真正的大语言环境经验扩展至少要同时扩展五件事。
第一是小世界生成规模化。智能体不能只在几个固定任务里学习,而要让大世界不断生成有边界、有目标、有工具、有反馈的小世界:代码、网页、办公、数据分析、多智能体协作、长期项目、私有工具和人类组织流程。这里的关键不是简单堆任务列表,而是让每个任务实例都能说明自己从大世界继承了什么、临时开放了什么、结束后允许回写什么。
第二是经验对象规模化。智能体要能产生更多尝试,但这些尝试必须被记录成可学习的经验对象。这里的重点不是让模型多试几次,而是把一次尝试拆成可分析的层次:它看到什么,内部怎样规划,提出什么动作请求,运行时执行了什么,外部环境发生什么变化,反馈指向哪一步,最后写到了哪里。
第三是验证规模化。经验扩展最终取决于可验证经验的供给。代码测试、编译器、网页状态、用户审查、制度规则和私有评测都是锚点,但它们成本不同、覆盖不同、可靠性也不同。规模化的关键不是把所有反馈都交给一个模型评判,而是建立验证预算:便宜验证覆盖大多数日常轨迹,昂贵验证抽查高风险或高价值经验,硬验证用于决定能否进入长期记忆、技能或数据资产。
第四是抽象和迁移规模化。单条经验的价值有限,真正的复利来自经验被抽象成可迁移的规则、记忆、案例和技能。一个数据分析智能体如果只是记住某次任务的答案,价值不大;如果能抽象出某类脏数据检查流程、某类建模错误诊断路径、某类报告生成惯例,才开始形成可复用能力。这里的难点是区分局部规律和通用规律:小世界里的成功不自动等于大世界里的知识。
第五是治理和回写规模化。经验一旦能被复用,就必须有来源、权限、安全状态和撤销机制。规模化不是把所有成功经验都推向权重,而是把经验放到合适的位置。低风险经验可以进短期记忆,稳定经验可以进项目规则,高价值经验可以进技能候选,跨任务验证后的经验可以进数据资产,权重更新则应放在最后。
持续强化学习可以放在这个飞轮里理解。一次性后训练可以让模型在某类任务上更强,但智能体部署后会持续遇到新代码库、新网页、新用户偏好、新工具版本、新组织规则和新安全边界。环境在变,任务在变,反馈来源也在变。如果学习只发生在离线训练阶段,智能体就很难真正从部署后的经验中复利。持续强化学习不是让权重随时被改,而是让上下文、记忆、规则、技能、数据和权重处在不同时间尺度的更新体系里。
一个可行方向是把持续学习拆成不同时间尺度。当前上下文负责分钟级适应,短期记忆负责任务级适应,项目规则和技能负责周级或月级复用,数据资产和权重更新负责更慢、更严格的能力内化。越往后,验证门槛越高,撤销成本也越高。
Hint:未来要收集的是经验对象,不是更多聊天日志。 一次交互至少要记录任务小世界的来源和边界、可见状态、内部计划摘要、实际动作、环境变化、反馈证据、验证强度、风险标签和最终更新去向。代码经验要保留补丁、测试和错误栈;网页经验要保留目标元素、点击前后状态和完成证据;办公经验要保留权限、审批、人类确认和偏好范围。收集之后还要做去重、脱敏、权限过滤、污染检测、失败归因、可回放整理和撤销索引。只有这样,部署后的交互数据才可能从发生过的历史,变成可以训练、可以审计、可以复用的经验。
后续研究也应该沿着同一个形式化收敛。 不需要把算法问题拆成很多互相分散的方向。沿着前面的经验对象和任务经验集合,核心算法问题可以对应到前面的三层。
第一,表示层算法要处理大而模糊的状态、观测和动作空间。它不只是把上下文塞满,而是学习哪些历史应该保留,哪些可以摘要,哪些必须作为验证证据保留,哪些内部变量代表当前任务真正的控制状态。对数学和证明任务,它还要表示内部符号状态和候选证明空间;对代码和网页任务,它要表示外部运行时状态和可落地动作。
第二,交互层算法要同时处理内部交互和外部交互。命令行智能体、浏览器智能体和办公智能体都可以完成复杂外部行动,但训练时仍要把内部计划、动作请求、运行时执行和外部效果分开;数学和证明任务也要把内部推理步骤、自我检查和最终答案分开。否则系统只知道一次任务失败了,却不知道该改观察、改内部任务环境、改计划、改工具参数,还是改权限和运行时。动作分解相关工作已经说明,这条路线能让语言智能体的行动空间更可训练(Wen et al., 2024)。
第三,耦合层算法要把策略、内部任务环境和价值判断一起看。算法需要决定什么时候相信测试,什么时候相信人类反馈,什么时候调用昂贵验证器,什么时候因为证据太弱而拒绝更新;也要判断一次经验应该更新策略、内部环境模型、价值/奖励判断、记忆、技能还是数据资产。持续强化学习不应等同于持续更新权重,因为同一个更新可能同时改变模型的行动方式、想象环境和自我评价标准。这本质上是多角色耦合下的多时间尺度控制问题。
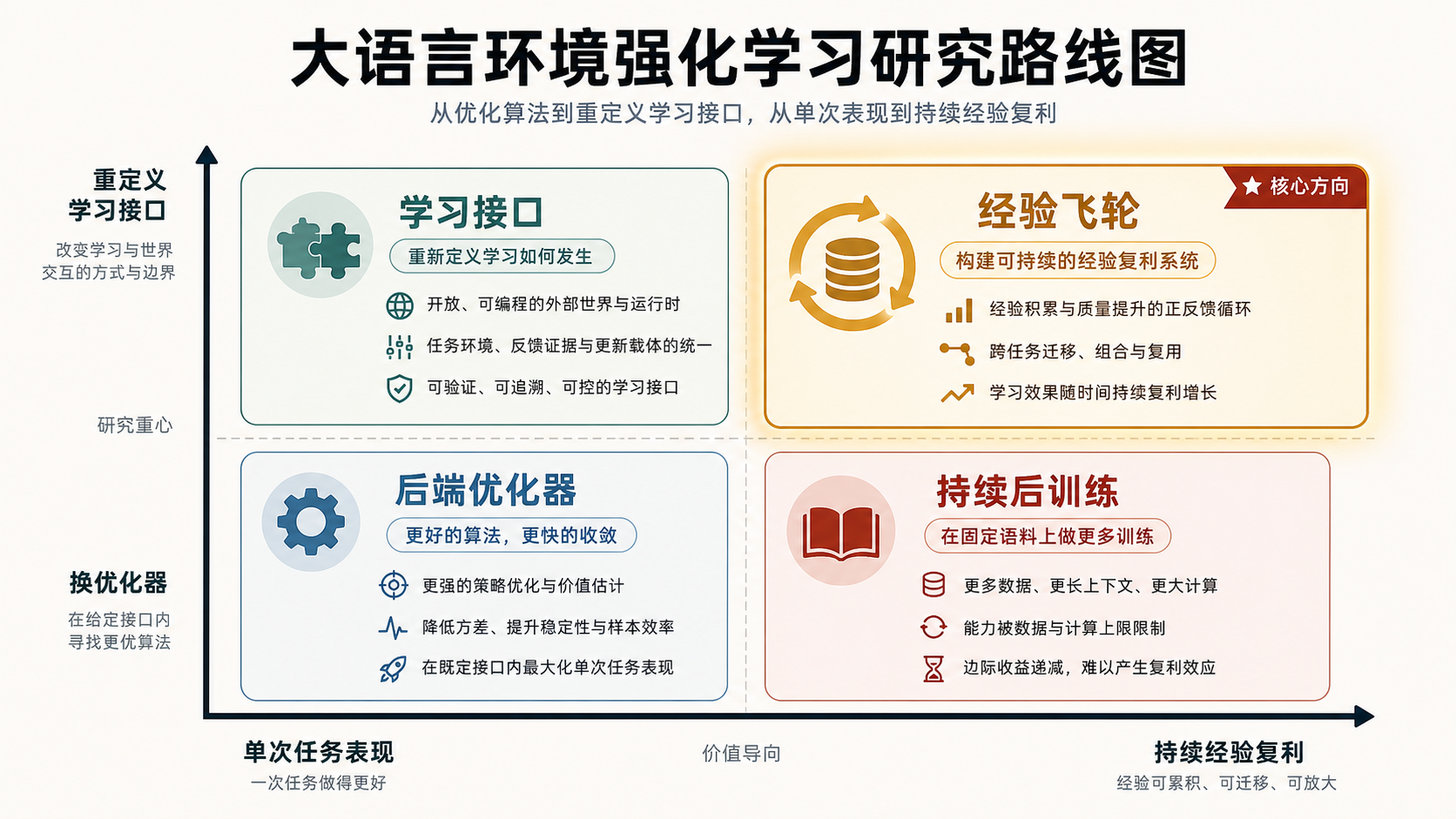
图 9 把这些方向放到一个坐标系里。横轴是从单次任务表现走向持续经验复利,纵轴是从只换后端优化器走向重新定义前端学习接口。核心方向不是把某个优化器做得更复杂,而是让优化器吃到正确的经验对象:状态和动作表示、内外环境交互、证据校准、信用分配和持续更新路由。
最后:从单次能力到持续经验
如果强化学习是答案,我们真正要问的问题不是怎样把 PPO、GRPO 或某个偏好优化算法套到智能体日志上,而是:大语言模型智能体到底在什么环境里学习,怎样把一个任务小世界中的行动、反馈和验证,转化为整个大世界中可复用、可撤销、可审计的经验。
这条线索把全文串起来。大语言环境不是单一外部模拟器,而是外部世界、运行时、内部任务环境、反馈证据和更新载体共同组成的学习场。每次任务都是从这个大世界中实例化出来的小世界。智能体在小世界里看见局部状态、做内部规划、发出动作请求、等待运行时落地、接收反馈证据。持续强化学习要解决的是,这些经验哪些只对当前小世界有效,哪些可以抽象成规则、记忆、技能或数据,哪些证据强到足以影响权重。
因此,大语言环境中的强化学习不是否定传统强化学习的累计回报目标,而是把原来常被固定下来的接口重新打开。状态和动作需要表示,内外环境需要区分,反馈需要先成为证据,奖励需要有锚点校准,更新需要有路由和撤销机制。只有这样,未来行为改善才不只是当前任务分数更高,而是未来更多任务小世界被更好地构造、更好地验证、更少被错误经验污染。
这也是从会回答到会积累经验的关键跨越。一个模型可以在单次任务里表现很强,却仍然不会持续学习;也可以在某次任务失败后,因为保留了正确证据、完成了失败归因、更新了合适载体,而让未来同类任务真正变好。智能体时代的经验扩展,核心不是日志越来越多,也不是权重更新越来越频繁,而是让大语言环境中的行动经验形成一个可靠飞轮:小世界产生经验,大世界吸收经验,新的小世界因此变得更容易被理解、被行动、被验证。
这就是大语言环境中的强化学习真正想解决的问题。它不是把自主自我改进当作口号,也不是把传统强化学习机械套到大模型上,而是把智能体如何从可验证经验中持续变好,变成一个可以记录、验证、审计和反驳的科学与工程问题。
参考文献
Sutton, R. S., and Barto, A. G. Reinforcement Learning: An Introduction. 2nd ed., MIT Press, 2018.
Silver, D., and Sutton, R. S. Welcome to the Era of Experience. 2025. Preprint chapter forthcoming in Designing an Intelligence, MIT Press.
Silver, D., Singh, S., Precup, D., and Sutton, R. S. Reward is Enough. Artificial Intelligence, 299:103535, 2021.
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s Verify Step by Step. arXiv:2305.20050, 2023.
Shao, Z. et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300, 2024.
Yao, S. et al. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023.
Wen, M., Wan, Z., Wang, J., Zhang, W., and Wen, Y. Reinforcing LLM Agents via Policy Optimization with Action Decomposition. NeurIPS 2024.
LangChain. Frameworks, runtimes, and harnesses. Docs by LangChain, accessed 2026-05-11.
Yang, J. et al. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. NeurIPS 2024.
Jimenez, C. E. et al. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770, 2023.
Zhou, S. et al. WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854, 2023.
Xie, T. et al. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. NeurIPS 2024.
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., and Gal, Y. AI Models Collapse When Trained on Recursively Generated Data. Nature 631, 755-759, 2024.